
In this tutorial, you’ll learn how to select all the different ways you can select columns in Pandas, either by name or index. You’ll learn how to use the loc, iloc accessors and how to select columns directly. You’ll also learn how to select columns conditionally, such as those containing a specific substring.
By the end of this tutorial, you’ll have learned:
- How to select columns by name or by index
- How to select all columns except for named columns
- How to select columns of a specific datatype
- How the
.locand.ilocaccessors work to select data in Pandas - How to select columns conditionally, such as those containing a string
Let’s get started!
Table of Contents
Loading a Sample Pandas DataFrame
To follow along with this tutorial, let’s load a sample Pandas DataFrame. By copying the code below, you’ll load a dataset that’s hosted on my Github page.
The DataFrame contains a number of columns of different data types, but few rows. This allows us to print out the entire DataFrame, ensuring us to follow along with exactly what’s going on.
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/SelectingColumns.csv')
print(df)
# Returns:
# Name Age Height Score Random_A Random_B Random_C Random_D Random_E
# 0 Joe 28 5'9 30 73 59 5 4 31
# 1 Melissa 26 5'5 32 30 85 38 32 80
# 2 Nik 31 5'11 34 80 71 59 71 53
# 3 Andrea 33 5'6 38 38 63 86 81 42
# 4 Jane 32 5'8 29 19 48 48 5 68Let’s break down what we’ve done here:
- We imported pandas using the alias
pd - We then loaded a DataFrame using the
pd.read_csv()function.
What Makes Up a Pandas DataFrame
Before diving into how to select columns in a Pandas DataFrame, let’s take a look at what makes up a DataFrame.
A DataFrame has both rows and columns. Each of the columns has a name and an index. For example, the column with the name 'Age' has the index position of 1.
As with other indexed objects in Python, we can also access columns using their negative index. For example, the column with the name 'Random_C' has the index position of -1.

Why Select Columns in Python?
The data you work with in lots of tutorials has very clean data with a limited number of columns. But this isn’t true all the time.
In many cases, you’ll run into datasets that have many columns – most of which are not needed for your analysis. In this case, you’ll want to select out a number of columns.
This often has the added benefit of using less memory on your computer (when removing columns you don’t need), as well as reducing the amount of columns you need to keep track of mentally.
How to Select a Single Column in Pandas
Pandas makes it easy to select a single column, using its name. We can do this in two different ways:
- Using dot notation to access the column
- Using square-brackets to access the column
Let’s see how we can do this by accessing the 'Name' column:
# Accessing a Single Column by Its Name
print(df['Name'])
# print(df.Name) (This returns the same value)
# Returns:
# 0 Joe
# 1 Melissa
# 2 Nik
# 3 Andrea
# 4 Jane
# Name: Name, dtype: object
Let’s take a quick look at why using the dot operator is often not recommended (while it’s easier to type). This is because you can’t:
- Select columns with spaces in the name,
- Use columns that have the same names as dataframe methods (such as ‘type’),
- Pick columns that aren’t strings, and
- Select multiple columns (as you’ll see later)
Now let’s take a look at what this actually returns. We can do this by using the type() function:
# Checking the Type of Our Column
print(type(df['Name']))
# Returns:
# <class 'pandas.core.series.Series'>We can see that selecting a single column returns a Pandas Series.
If we wanted to return a Pandas DataFrame instead, we could use double square-brackets to make our selection. Let’s see what this looks like:
# Selecting a Single Column as a Pandas DataFrame
print(type(df[['Name']]))
# Returns:
# <class 'pandas.core.frame.DataFrame'>What we’re actually doing here is passing in a list of columns to select. In this case, we’re passing in a list with a single item. When a list is passed in to the selector, a DataFrame is returned.
In the following section, you’ll learn how to select multiple columns in a Pandas DataFrame.
How to Select Multiple Columns in Pandas
Selecting multiple columns works in a very similar way to selecting a single column. We can pass a list of column names into our selection in order to select multiple columns. Because we need to pass in a list of items, the . notation is not possible when selecting multiple columns.
Let’s take a look at how we can select the the Name, Age, and Height columns:
# Selecting Multiple Columns in a Pandas DataFrame
selection = df[['Name', 'Age', 'Height']]
print(selection)
# Returns:
# Name Age Height
# 0 Joe 28 5'9
# 1 Melissa 26 5'5
# 2 Nik 31 5'11
# 3 Andrea 33 5'6
# 4 Jane 32 5'8What’s great about this method, is that you can return columns in whatever order you want. If you wanted to switch the order around, you could just change it in your list:
# Selecting Columns in a Different Order
selection = df[['Name', 'Height', 'Age']]
print(selection)
# Returns:
# Name Height Age
# 0 Joe 5'9 28
# 1 Melissa 5'5 26
# 2 Nik 5'11 31
# 3 Andrea 5'6 33
# 4 Jane 5'8 32In the next section, you’ll learn how to select columns by data type in Pandas.
How to Select Columns by Data Type in Pandas
In this section, you’ll learn how to select Pandas columns by specifying a data type in Pandas. This method allows you to, for example, select all numeric columns. This can be done by using the, aptly-named, .select_dtypes() method.
Let’s take a look at how we can select only text columns, which are stored as the 'object' data type:
# Selecting a Data Type with Pandas
selection = df.select_dtypes('object')
print(selection)
# Returns:
# Name Height
# 0 Joe 5'9
# 1 Melissa 5'5
# 2 Nik 5'11
# 3 Andrea 5'6
# 4 Jane 5'8The data types that are available can be a bit convoluted. The list below breaks down some of the common ones you may encounter:
- Numeric data types:
np.numberor'number' - Strings:
'object' - Datetimes:
np.datetime64,'datetime'or'datetime64' - Timedeltas:
np.timedelta64,'timedelta'or'timedelta64' - Categorical:
'category' - Datetimes with Timezones:
'datetimetz'or'datetime64[ns, tz]'
Using loc to Select Columns
The .loc accessor is a great way to select a single column or multiple columns in a dataframe if you know the column name(s).
This method is great for:
- Selecting columns by column name,
- Selecting columns using a single label, a list of labels, or a slice
The loc method looks like this:
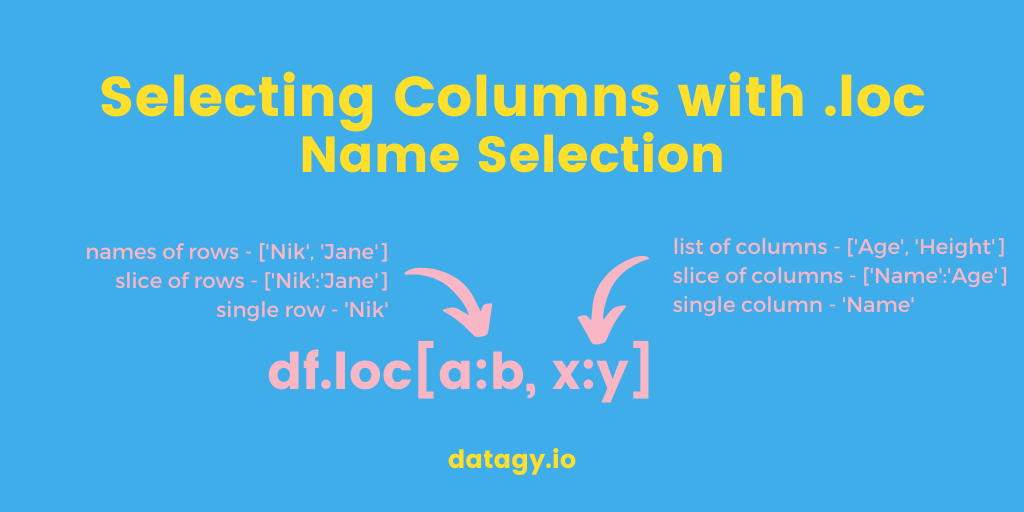
In the image above, you can see that you need to provide some list of rows to select. In many cases, you’ll want to select all rows (if your intention is to select columns). Because of this, you can pass in simply a colon (:), which selects all rows.
Let’s see how we can select all rows belonging to the name column, using the .loc accessor:
# Using .loc to Select Columns
print(df.loc[:, 'Name'])
# Returns:
# 0 Joe
# 1 Melissa
# 2 Nik
# 3 Andrea
# 4 Jane
# Name: Name, dtype: objectNow, if you wanted to select only the name column and the first three rows, you could write:
# Using .loc to Select Rows and Columns
selection = df.loc[:2,'Name']
print(selection)
# Returns:
# 0 Joe
# 1 Melissa
# 2 NikSelecting Multiple Columns with .loc in Pandas
Similarly, Pandas makes it easy to select multiple columns using the .loc accessor. We can include a list of columns to select. For example, if we wanted to select the 'Name' and 'Height' columns, we could pass in the list ['Name', 'Height'] as shown below:
# Selecting Multiple Columns Using .loc
print(df.loc[:, ['Name', 'Height']])
# Returns:
# Name Height
# 0 Joe 5'9
# 1 Melissa 5'5
# 2 Nik 5'11
# 3 Andrea 5'6
# 4 Jane 5'8We can also select a slice of columns using the .loc accessor. This works a little differently, as we don’t need to pass in a list, but rather a slice of column names. Say we wanted to select all columns from the 'Name' to 'Score' columns, we could write:
# Selecting a Slice of Columns in Pandas
print(df.loc[:, 'Name':'Score'])
# Returns:
# Name Age Height Score
# 0 Joe 28 5'9 30
# 1 Melissa 26 5'5 32
# 2 Nik 31 5'11 34
# 3 Andrea 33 5'6 38
# 4 Jane 32 5'8 29As a quick recap, the .loc accessor is great for selecting columns and rows by their names. In the following section, you’ll learn about the .iloc accessor, which lets you access rows and columns by their index position.
Using iloc to Select Columns
The iloc function is one of the primary way of selecting data in Pandas. The method “iloc” stands for integer location indexing, where rows and columns are selected using their integer positions.
This method is great for:
- Selecting columns by column position (index),
- Selecting columns using a single position, a list of positions, or a slice of positions
The standard format of the iloc method looks like this:

Now, for example, if we wanted to select the first two columns of our dataframe, we could write:
# Selecting a Range of Columns with .iloc
print(df.iloc[ : , :2])
# Returns:
# Name Age
# 0 Joe 28
# 1 Melissa 26
# 2 Nik 31
# 3 Andrea 33
# 4 Jane 32Note that we didn’t write df.iloc[:,0:2], but that would have yielded the same result.
If we wanted to select all columns and only two rows with .iloc, we could do that by writing:
selection = df.iloc[:2,]
print(selection)This returns:
Name Age Height Score Random_A Random_B Random_C Random_D Random_E
0 Joe 28 5'9 30 73 59 5 4 31
1 Melissa 26 5'5 32 30 85 38 32 80How to Select Column Names Containing a String in Pandas
There may be times when you want to select columns that contain a certain string. This can, for example, be helpful if you’re looking for columns containing a particular unit. In our example below, we’re selecting columns that contain the string 'Random'.
Since the .loc accessor can accept a list of columns, we can write a list comprehension in the accessor to filter out column names meeting our condition. Let’s see what this looks like:
# Selecting Columns Meeting a Condition
print(df.loc[ : , [col for col in df.columns if 'Random' in col]])
# Returns:
# Random_A Random_B Random_C Random_D Random_E
# 0 73 59 5 4 31
# 1 30 85 38 32 80
# 2 80 71 59 71 53
# 3 16 63 86 81 42
# 4 19 40 48 5 68How to Select Columns Meeting a Condition
Similarly, we can select columns where the values meet a condition. We can also do this by using a list comprehension. In the comprehension, we’ll write a condition to evaluate against.
Say we wanted to filter down to only columns where any value is equal to 30. In this case, we could write the following:
# Selecting Columns Where Values Meet a Condition
print(df.loc[ : , [(df[col] == 30).any() for col in df.columns]])
# Returns:
# Score Random_A
# 0 30 73
# 1 32 30
# 2 34 80
# 3 38 16
# 4 29 19Let’s break down what we did here:
- We used to
.ilocaccessor to access all rows - We then used a list comprehension to select column names meeting a condition
- Our condition returns any column where any of the values are equal to 30 in that column
Copying Columns vs. Selecting Columns
Something important to note for all the methods covered above, it might looks like fresh dataframes were created for each. However, that’s not the case!
In Python, the equal sign (“=”), creates a reference to that object.
Because of this, you’ll run into issues when trying to modify a copied dataframe.
In order to avoid this, you’ll want to use the .copy() method to create a brand new object, that isn’t just a reference to the original.
To accomplish this, simply append .copy() to the end of your assignment to create the new dataframe.
For example, if we wanted to create a filtered dataframe of our original that only includes the first four columns, we could write:
new_df = df.iloc[:,:4].copy()
print(new_df)This results in this code below:
Name Age Height Score
0 Joe 28 5'9 30
1 Melissa 26 5'5 32
2 Nik 31 5'11 34
3 Andrea 33 5'6 38
4 Jane 32 5'8 29This is incredibly helpful if you want to work the only a smaller subset of a dataframe.
Conclusion: Using Pandas to Select Columns
In this tutorial, you learned how to use Pandas to select columns. You learned how to use many different methods to select columns, including using square brackets to select a single or multiple columns. You then learned many different ways to use the .loc and .iloc accessors to select columns.
You learned some unique ways of selecting columns, such as when column names contain a string and when a column contains a particular value.
Additional Resources
To learn more about related topics, check out the tutorials below:
Pingback: Rename Pandas Columns with Pandas .rename() • datagy
Pingback: All the Ways to Filter Pandas Dataframes • datagy
Pingback: Pandas Quantile: Calculate Percentiles of a Dataframe • datagy
Pingback: Calculate the Pearson Correlation Coefficient in Python • datagy
Pingback: Indexing, Selecting, and Assigning Data in Pandas • datagy