
In this tutorial, you’ll learn how to index, select and assign data in a Pandas DataFrame. Understanding how to index and select data is an important first step in almost any exploratory work you’ll take on in data science. Similarly, knowing how to assign values in Pandas can open up a whole new world potential when working with DataFrames.
Table of Contents
Loading a Sample Pandas Dataframe
To start things off, let’s load our pandas DataFrame again. We’ll use a DataFrame that contains mock information on sales across different regions over the period of a year. The dataset is hosted on the datagy Github page and can be loaded directly into a pandas DataFrame. Let’s create a DataFrame named df, which will hold all of our data:
# Loading our Pandas DataFrame
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/sales.csv')The Two Types of DataFrame Indices
A pandas DataFrame can be thought of as many different pandas Series objects collected together. A pandas Series already has an index, which in the case of a pandas DataFrame is a row value. However, a pandas DataFrame also has a column index, which is represented by the column position. Because of this, a pandas DataFrame actually has two indices!
We differentiate these indices by their axis. An index that is along axis 0 is the row index, while the index that is along axis 1 is the column index. The intersection of these two indices is represented by a particular value.
This may seem a bit confusing and, perhaps even, a bit unnecessary. However, it opens up quite a bit of possibility! It allows to, for example, access values not just based on their position, but also by their label. This can be quite helpful when you want to parse out just a particular value, but don’t know where it’s located, just that it exists.
Accessing Columns in a Pandas DataFrame
There are two main ways in which we can access entire columns in Pandas:
- Using
.(dot) notation, or - Using
[](square-bracket) indexing
Let’s see how we can access a particular column in our pandas DataFrame using the dot notation method:
# Accesing the 'date' column in a Pandas DataFrame
print(df.date)
# Returns:
# 0 8/22/2022
# 1 3/5/2022
# 2 2/9/2022
# 3 6/22/2022
# 4 8/10/2022
# ...
# 995 6/2/2022
# 996 5/20/2022
# 997 4/2/2022
# 998 12/7/2022
# 999 12/19/2022
# Name: date, Length: 1000, dtype: objectWhat’s interesting about selecting a pandas DataFrame column is that it actually returns a pandas Series object! We can verify this by passing the column as an argument into the type() function:
# Checking the type of a Pandas DataFrame column
print(type(df.date))
# Returns: <class 'pandas.core.series.Series'>Similarly, we can access the gender column using the square-bracket notionation:
# Selecting a column with square brackets
print(df['gender'])
# Returns:
# 0 Male
# 1 Male
# 2 Male
# 3 Male
# 4 Female
# ...
# 995 Female
# 996 Female
# 997 Male
# 998 Male
# 999 Female
# Name: gender, Length: 1000, dtype: objectUnder the hood, both of these methods work exactly the same. So why choose one over the other? The square-bracket indexing method allows us to both select columns that use reserved words and select columns that have spaces in them. My personal preference is to use the square-bracket method as it will work without fail. While it may seem like it takes longer to write, it does yield consistently valid results!
Another benefit of using the square-brackets method to select columns is that we can actually select multiple columns! We can wrap the column we want to select in a list and pass that in. Say we wanted to select the gender and region columns, we could write the following code:
# Selecting multiple columns in a Pandas DataFrame
print(df[['gender', 'region']])
# Returns:
# gender region
# 0 Male North-West
# 1 Male North-East
# 2 Male North-East
# 3 Male North-East
# 4 Female North-West
# .. ... ...
# 995 Female North-West
# 996 Female North-East
# 997 Male North-East
# 998 Male North-East
# 999 Female North-West
# [1000 rows x 2 columns]There’s a couple of things to note here:
- We need to wrap our selection in what looks like double square-brackets, and
- This actually returns a Pandas DataFrame, rather than a Series
Now that you have an understanding of how to select columns in Pandas, let’s move on to selecting rows – which is what you’ll learn in the following section.
Accessing Rows in a Pandas DataFrame
Accessing rows in Pandas works slightly differently than accessing columns, but it’s also incredibly intuitive. We’ll need to cover off a bit of theory before learning about accessing rows. This is because accessing rows works in conjunction with selecting columns.
Before we dive into actually selecting rows, let’s look at two types of accessors available in pandas: .loc[] and .iloc[]. Let’s start off looking at the .loc[] operator, which is known as label-based selection. With this, we can access columns, rows and values using their labels!
Using loc to Select Rows in a Pandas Dataframe
The image below breaks down how to select data with the .loc operator. The operator is separated into two attributes, separated by commas. We place the row selection into the first part, and the column selection into the second one.
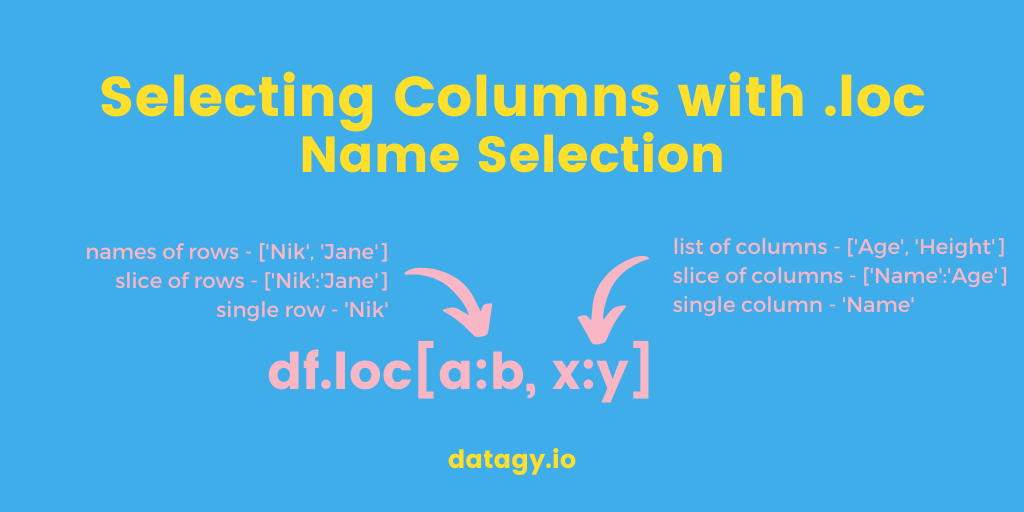
This works very similar to indexing lists in Pythom where we can use a colon (:) to denote selecting an entire list. This means that we can parse our a particular row by selecting its row index and simply selecting all columns!
Let’s see how we can access the first row using the .loc operator:
# Accessing the first row in a Pandas dataframe
print(df.loc[0, :])
# Returns:
# date 8/22/2022
# gender Male
# region North-West
# sales 20381
# Name: 0, dtype: objectHere we access the row by its label: 0. This is the label that’s assigned in the index. Pandas will, by default, assign indices from 0 through to end of the dataframe. In this case, 0 refers both to its label and its position.
Want to simplify this even further?
Since we’re actually just accessing the row (and all its columns), we can omit the comma and the colon entirely. Writing df.loc[0] would return the exact same thing!
Using iloc to Select Rows in a Pandas Dataframe
Now, let’s take a look at how we can select a row (or rows) using their positions. This can be done by using the .iloc operator. The operator follows the same convention of first identifying rows and then columns. The image below shows how to select data with the .iloc operator:

So, say we wanted to access the first row, could simply access the 0th row and all the columns.
# Accessing the first row in a Pandas dataframe
print(df.iloc[0, :])
# Returns:
# date 8/22/2022
# gender Male
# region North-West
# sales 20381
# Name: 0, dtype: objectRemember, while this method looks the same compared to the .loc operator, here we are accessing the 0th position, whereas earlier we were accessing the label “0”.
Now, try to write a line of code that would access the third through the fifth rows. Toggle the section below to see the solution.
How would you access rows 3, 4, and 5 in a Pandas DataFrame, df?
Any of the solutions below would work:
# Accessing the third through fifth rows of a Pandas DataFrame
print(df.iloc[2:5, :])
print(df.iloc[2:5])
print(df.iloc[[2,3,4], :])
print(df.iloc[[2,3,4]])In the next section, you’ll learn how to select specific values in a pandas DataFrame.
Accessing Values in a Pandas DataFrame
Now that you know how to select both rows and columns in pandas, we can use what you’ve learned to select specific data points. We can do this by using either .loc or .iloc, depending on what best suits our needs.
Because we don’t always know the position of our columns, it may make sense to start with the .loc accessor. Say we wanted to select the row with the label "0" and the column "sales", we could write the following code:
# Accessing a value in Pandas
print(df.loc[0, 'sales'])
# Returns: 20381Now, say we wanted to access the last row’s value for the 'sales' column. In order to this, we need to use the .iloc accessor, so that we can easily apply negative indexing. Remember, negative indexing begins at the value of -1.
# Accessing the last value for sales
print(df.iloc[-1, 3])
# Returns: 16589Now that you know how to select particular values based on their labels and positions, it’s time to move onto something a bit more complex. In the next section, you’ll learn how to select rows conditionally!
Selecting Data Conditionally In a Pandas Dataframe
Many interesting data manipulations require us to look at data conditionally. That’s what you’ll learn in this section: how to select data conditionally. Let’s say we wanted to select rows where our sales where a part of the North-West region. Let’s try seeing what this condition looks like:
# Applying a condition to a dataframe column
print(df['region'] == 'North-West')
# Returns:
# 0 True
# 1 False
# 2 False
# 3 False
# 4 True
# ...
# 995 True
# 996 False
# 997 False
# 998 False
# 999 True
# Name: region, Length: 1000, dtype: boolLet’s break down what’s going on here:
- We use the
==operator to evaluate a condition. - The datatype (
dtype) of the returned series is aboolean - This returns a boolean series that evaluates whether the row meets our condition or not
You may be thinking that this series isn’t particular useful. However, we can apply the series into our DataFrame to filter our rows! In order to do this, we index the boolean Series. Let’s see what this looks like:
print(df[df['region'] == 'North-West'])
# Returns:
# date gender region sales
# 0 8/22/2022 Male North-West 20381
# 4 8/10/2022 Female North-West 15007
# 7 7/8/2022 Male North-West 13650
# 11 4/30/2022 Female North-West 19631
# 16 4/18/2022 Male North-West 17397
# .. ... ... ... ...
# 988 7/10/2022 Male North-West 12500
# 989 10/14/2022 Female North-West 15319
# 993 6/11/2022 Male North-West 14942
# 995 6/2/2022 Female North-West 14015
# 999 12/19/2022 Female North-West 16589
# [322 rows x 4 columns]That was easy! We can even combine our conditions to further refine our conditions by using either the & (and) operator or the | (or) operator. This follows normal Python truth tables. Say we wanted to select rows where the region was ‘North-West’ and the sales were over 15000. For this, we could write:
# Combining conditions when selecting data
print(df[(df['region'] == 'North-West') & (df['sales'] > 15000)])
# Returns:
# date gender region sales
# 0 8/22/2022 Male North-West 20381
# 4 8/10/2022 Female North-West 15007
# 11 4/30/2022 Female North-West 19631
# 16 4/18/2022 Male North-West 17397
# 17 7/30/2022 Female North-West 16668
# .. ... ... ... ...
# 974 5/6/2022 Female North-West 15112
# 983 11/21/2022 Male North-West 17904
# 987 2/7/2022 Male North-West 16905
# 989 10/14/2022 Female North-West 15319
# 999 12/19/2022 Female North-West 16589
# [175 rows x 4 columns]Note that in order to make this work, we need to wrap our conditions in regular parentheses. In the final section of this lesson, you’ll learn about how to assign data in a Pandas DataFrame.
Assigning Data in Pandas
In this final section, you’ll learn how start assigning values to a Pandas DataFrame. Because this is a fairly broad topic, you’ll learn about only a few methods in order to assign data.
Assigning a Value to an Entire Column
The first way to assigns values in Pandas is to assign a value to an entire column. Say we wanted to add a column that described the country and we wanted to add the value 'USA' to every record. We could simply assign a new value and pass in the string:
# Assign a Value to an Entire Column
df['country'] = 'USA'
print(df.head(3))
# Returns:
# date gender region sales country
# 0 8/22/2022 Male North-West 20381 USA
# 1 3/5/2022 Male North-East 14495 USA
# 2 2/9/2022 Male North-East 13510 USAAssign a Value to a Particular Cell
We can also use .loc or .iloc to set a particular value. In order to do this, we first access the particular row and column combination and then use the assignment operator, =, to assign a value. Let’s say we wanted to change the first record’s gender value to ‘Female’. We could do this by using .iloc:
# Changing a cell's value
df.iloc[0,1] = 'Female'
print(df.head(3))
# Returns
# date gender region sales
# 0 8/22/2022 Female North-West 20381
# 1 3/5/2022 Male North-East 14495
# 2 2/9/2022 Male North-East 13510In this example, we accessed the first record and the second column using the .iloc and then assigned our value.
Exercises
In order to solidify your learning, check out the exercises below. The solutions are available by toggling the item below:
Replicate the .tail() method to select the last five rows of a Pandas DataFrame.
df.iloc[-5:]Select rows from the South region where sales were over 15000.
df[(df['region'] == 'South') & (df['sales'] > 15000)]Assign the first record in the third column the value of South.
df.iloc[0,2] = 'South'Conclusion and Recap
In this tutorial, you learned about selecting and assigning data in a Pandas DataFrame. Both these skills are foundational Pandas skills that may require a bit of referencing as you progress in your Pandas journey. Below, you’ll find a high-level summary of what you learned:
- Pandas DataFrames have two indices: a row index and a column index
- Select a column returns a Pandas series. Selecting multiple columns returns a dataframe.
- We can use
.ilocaccessors to access data based on their position and.locaccessors to access data based on their labels - We can select data conditionally using boolean series and indexing the dataframe
- We can assign data in many different ways, including using the
.ilocand.locaccessors
Additional Resources
To learn more about related topics, check out the articles listed below:
Hi there, great refresher so far, thank you for sharing!
You have a typo in the answer on the question 1. It should be:
df.iloc[-5:]
Thanks so much, Nikola! I appreciate it. I have made the update :).