
In this tutorial, you’ll learn how to use Python and Pandas to read Excel files using the Pandas read_excel function. Excel files are everywhere – and while they may not be the ideal data type for many data scientists, knowing how to work with them is an essential skill.
By the end of this tutorial, you’ll have learned:
- How to use the Pandas read_excel function to read an Excel file
- How to read specify an Excel sheet name to read into Pandas
- How to read multiple Excel sheets or files
- How to certain columns from an Excel file in Pandas
- How to skip rows when reading Excel files in Pandas
- And more
Let’s get started!
Table of Contents
The Quick Answer: Use Pandas read_excel to Read Excel Files
To read Excel files in Python’s Pandas, use the read_excel() function. You can specify the path to the file and a sheet name to read, as shown below:
# Reading an Excel File in Pandas
import pandas as pd
df = pd.read_excel('/Users/datagy/Desktop/Sales.xlsx')
# With a Sheet Name
df = pd.read_excel(
io='/Users/datagy/Desktop/Sales.xlsx'
sheet_name ='North'
)In the following sections of this tutorial, you’ll learn more about the Pandas read_excel() function to better understand how to customize reading Excel files.
Understanding the Pandas read_excel Function
The Pandas read_excel() function has a ton of different parameters. In this tutorial, you’ll learn how to use the main parameters available to you that provide incredible flexibility in terms of how you read Excel files in Pandas.
| Parameter | Description | Available Option |
|---|---|---|
io= | The string path to the workbook. | URL to file, path to file, etc. |
sheet_name= | The name of the sheet to read. Will default to the first sheet in the workbook (position 0). | Can read either strings (for the sheet name), integers (for position), or lists (for multiple sheets) |
usecols= | The columns to read, if not all columns are to be read | Can be strings of columns, Excel-style columns (“A:C”), or integers representing positions columns |
dtype= | The datatypes to use for each column | Dictionary with columns as keys and data types as values |
skiprows= | The number of rows to skip from the top | Integer value representing the number of rows to skip |
nrows= | The number of rows to parse | Integer value representing the number of rows to read |
.read_excel() functionThe table above highlights some of the key parameters available in the Pandas .read_excel() function. The full list can be found in the official documentation. In the following sections, you’ll learn how to use the parameters shown above to read Excel files in different ways using Python and Pandas.
How to Read Excel Files in Pandas read_excel
As shown above, the easiest way to read an Excel file using Pandas is by simply passing in the filepath to the Excel file. The io= parameter is the first parameter, so you can simply pass in the string to the file.
The parameter accepts both a path to a file, an HTTP path, an FTP path or more. Let’s see what happens when we read in an Excel file hosted on my Github page.
# Reading an Excel file in Pandas
import pandas as pd
df = pd.read_excel('https://github.com/datagy/mediumdata/raw/master/Sales.xlsx')
print(df.head())
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 191
# 1 2022-04-02 B 727
# 2 2022-04-03 A 782
# 3 2022-04-04 B 561
# 4 2022-04-05 A 969If you’ve downloaded the file and taken a look at it, you’ll notice that the file has three sheets? So, how does Pandas know which sheet to load? By default, Pandas will use the first sheet (positionally), unless otherwise specified.
In the following section, you’ll learn how to specify which sheet you want to load into a DataFrame.
How to Specify Excel Sheet Names in Pandas read_excel
As shown in the previous section, you learned that when no sheet is specified, Pandas will load the first sheet in an Excel workbook. In the workbook provided, there are three sheets in the following structure:
Sales.xlsx
|---East
|---West
|---NorthBecause of this, we know that the data from the sheet “East” was loaded. If we wanted to load the data from the sheet “West”, we can use the sheet_name= parameter to specify which sheet we want to load.
The parameter accepts both a string as well as an integer. If we were to pass in a string, we can specify the sheet name that we want to load.
Let’s take a look at how we can specify the sheet name for 'West':
# Specifying an Excel Sheet to Load by Name
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name='West')
print(df.head())
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 504
# 1 2022-04-02 B 361
# 2 2022-04-03 A 694
# 3 2022-04-04 B 702
# 4 2022-04-05 A 255Similarly, we can load a sheet name by its position. By default, Pandas will use the position of 0, which will load the first sheet. Say we wanted to repeat our earlier example and load the data from the sheet named 'West', we would need to know where the sheet is located.
Because we know the sheet is the second sheet, we can pass in the 1st index:
# Specifying an Excel Sheet to Load by Position
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name=1)
print(df.head())
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 504
# 1 2022-04-02 B 361
# 2 2022-04-03 A 694
# 3 2022-04-04 B 702
# 4 2022-04-05 A 255We can see that both of these methods returned the same sheet’s data. In the following section, you’ll learn how to specify which columns to load when using the Pandas read_excel function.
How to Specify Columns Names in Pandas read_excel
There may be many times when you don’t want to load every column in an Excel file. This may be because the file has too many columns or has different columns for different worksheets.
In order to do this, we can use the usecols= parameter. It’s a very flexible parameter that lets you specify:
- A list of column names,
- A string of Excel column ranges,
- A list of integers specifying the column indices to load
Most commonly, you’ll encounter people using a list of column names to read in. Each of these columns are comma separated strings, contained in a list.
Let’s load our DataFrame from the example above, only this time only loading the 'Customer' and 'Sales' columns:
# Specifying Columns to Load by Name
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
usecols=['Customer', 'Sales'])
print(df.head())
# Returns:
# Customer Sales
# 0 A 191
# 1 B 727
# 2 A 782
# 3 B 561
# 4 A 969We can see that by passing in the list of strings representing the columns, we were able to parse those columns only.
If we wanted to use Excel changes, we could also specify columns 'B:C'. Let’s see what this looks like below:
# Specifying Columns to Load by Excel Range
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
usecols='B:C')
print(df.head())
# Returns:
# Customer Sales
# 0 A 191
# 1 B 727
# 2 A 782
# 3 B 561
# 4 A 969Finally, we can also pass in a list of integers that represent the positions of the columns we wanted to load. Because the columns are the second and third columns, we would load a list of integers as shown below:
# Specifying Columns to Load by Their Position
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
usecols=[1,2])
print(df.head())
# Returns:
# Customer Sales
# 0 A 191
# 1 B 727
# 2 A 782
# 3 B 561
# 4 A 969In the following section, you’ll learn how to specify data types when reading Excel files.
How to Specify Data Types in Pandas read_excel
Pandas makes it easy to specify the data type of different columns when reading an Excel file. This serves three main purposes:
- Preventing data from being read incorrectly
- Speeding up the read operation
- Saving memory
You can pass in a dictionary where the keys are the columns and the values are the data types. This ensures that data are ready correctly. Let’s see how we can specify the data types for our columns.
# Specifying Data Types for Columns When Reading Excel Files
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
dtype={'date':'datetime64', 'Customer': 'object', 'Sales':'int'})
print(df.head())
# Returns:
# Customer Sales
# Date Customer Sales
# 0 2022-04-01 A 191
# 1 2022-04-02 B 727
# 2 2022-04-03 A 782
# 3 2022-04-04 B 561
# 4 2022-04-05 A 969It’s important to note that you don’t need to pass in all the columns for this to work. In the next section, you’ll learn how to skip rows when reading Excel files.
How to Skip Rows When Reading Excel Files in Pandas
In some cases, you’ll encounter files where there are formatted title rows in your Excel file, as shown below:
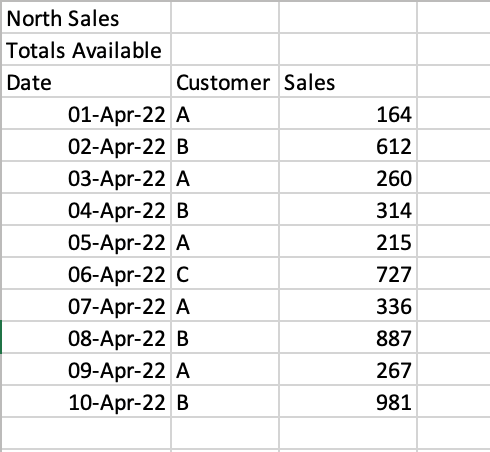
If we were to read the sheet 'North', we would get the following returned:
# Reading a poorly formatted Excel file
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name='North')
print(df.head())
# Returns:
# North Sales Unnamed: 1 Unnamed: 2
# 0 Totals Available NaN NaN
# 1 Date Customer Sales
# 2 2022-04-01 00:00:00 A 164
# 3 2022-04-02 00:00:00 B 612
# 4 2022-04-03 00:00:00 A 260Pandas makes it easy to skip a certain number of rows when reading an Excel file. This can be done using the skiprows= parameter. We can see that we need to skip two rows, so we can simply pass in the value 2, as shown below:
# Reading a Poorly Formatted File Correctly
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name='North',
skiprows=2)
print(df.head())
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 164
# 1 2022-04-02 B 612
# 2 2022-04-03 A 260
# 3 2022-04-04 B 314
# 4 2022-04-05 A 215This read the file much more accurately! It can be a lifesaver when working with poorly formatted files. In the next section, you’ll learn how to read multiple sheets in an Excel file in Pandas.
How to Read Multiple Sheets in an Excel File in Pandas
Pandas makes it very easy to read multiple sheets at the same time. This can be done using the sheet_name= parameter. In our earlier examples, we passed in only a single string to read a single sheet. However, you can also pass in a list of sheets to read multiple sheets at once.
Let’s see how we can read our first two sheets:
# Reading Multiple Excel Sheets at Once in Pandas
import pandas as pd
dfs = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name=['East', 'West'])
print(type(dfs))
# Returns: <class 'dict'>In the example above, we passed in a list of sheets to read. When we used the type() function to check the type of the returned value, we saw that a dictionary was returned.
Each of the sheets is a key of the dictionary with the DataFrame being the corresponding key’s value. Let’s see how we can access the 'West' DataFrame:
# Reading Multiple Excel Sheets in Pandas
import pandas as pd
dfs = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name=['East', 'West'])
print(dfs.get('West').head())
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 504
# 1 2022-04-02 B 361
# 2 2022-04-03 A 694
# 3 2022-04-04 B 702
# 4 2022-04-05 A 255You can also read all of the sheets at once by specifying None for the value of sheet_name=. Similarly, this returns a dictionary of all sheets:
# Reading Multiple Excel Sheets in Pandas
import pandas as pd
dfs = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
sheet_name=None)In the next section, you’ll learn how to read multiple Excel files in Pandas.
How to Read Only n Lines When Reading Excel Files in Pandas
When working with very large Excel files, it can be helpful to only sample a small subset of the data first. This allows you to quickly load the file to better be able to explore the different columns and data types.
This can be done using the nrows= parameter, which accepts an integer value of the number of rows you want to read into your DataFrame. Let’s see how we can read the first five rows of the Excel sheet:
# Reading n Number of Rows of an Excel Sheet
import pandas as pd
df = pd.read_excel(
io='https://github.com/datagy/mediumdata/raw/master/Sales.xlsx',
nrows=5)
print(df)
# Returns:
# Date Customer Sales
# 0 2022-04-01 A 191
# 1 2022-04-02 B 727
# 2 2022-04-03 A 782
# 3 2022-04-04 B 561
# 4 2022-04-05 A 969Conclusion
In this tutorial, you learned how to use Python and Pandas to read Excel files into a DataFrame using the .read_excel() function. You learned how to use the function to read an Excel, specify sheet names, read only particular columns, and specify data types. You then learned how skip rows, read only a set number of rows, and read multiple sheets.
Additional Resources
To learn more about related topics, check out the tutorials below:
Nice summary of pandas read_excel 🙂
Is there a way to read an excel file while it is open in Excel?
I think this is an interesting safe guard: when the file is open, it have changes made it to it since the last time it was saved. But I agree, it feels like an odd limitation!