
In this tutorial, you’ll learn how to use Pandas to drop an index column. Dropping a Pandas DataFrame index column allows you to remove unwanted columns or to restructure your dataset in meaningful ways. You’ll learn how to do this using the .reset_index() DataFrame method, the .set_index() method, and how to read and write CSV files without an index.
As you create a DataFrame, Pandas will attempt to infer an index column. While many times these indices are relevant, there may times when you simply want to remove the index. Pandas provides a number of helpful ways of doing this, either after a DataFrame is loaded or prior to loading the DataFrame.
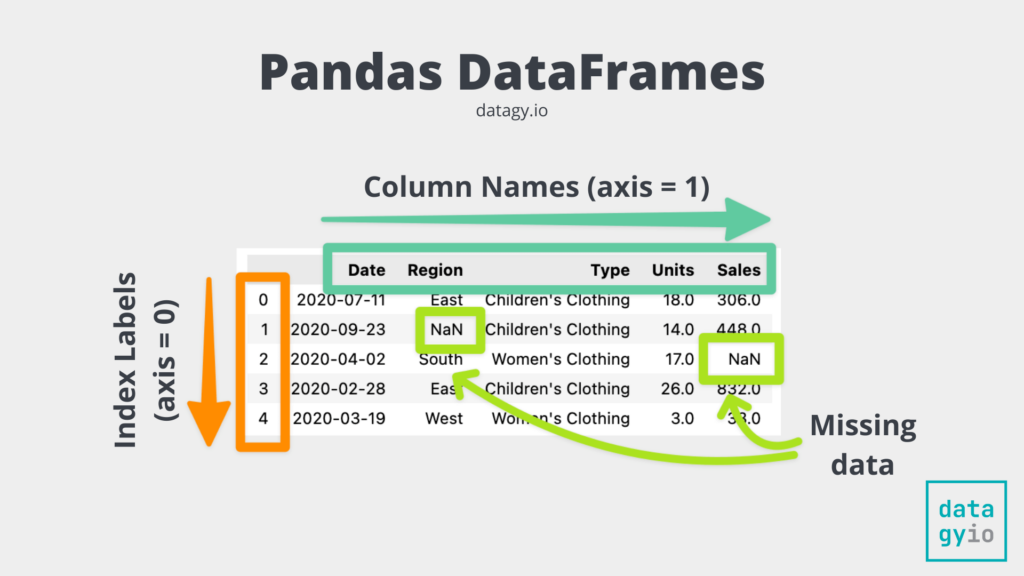
The image below provides an overview of what you’ll learn in this tutorial – how to drop a Pandas DataFrame index column:

The Quick Answer: Use Pandas .reset_index(drop=True) to Drop an Index Column
# Dropping an Index Column in Pandas
import pandas as pd
df = pd.DataFrame.from_dict({
'Name': ['Jane', 'Nik', 'Kate', 'Melissa'],
'Age': [10, 35, 34, 23]
}).set_index('Name')
df = df.reset_index(drop=True)Let’s get started!
Table of Contents
What is a Pandas Index Column?
The Pandas index is analogous to an Excel row number. But simply saying only that would do the index a great disservice. This is because it’s much, much more than a row number. We can think of the row index as the way to access a DataFrame’s records – similar to an address or a dictionary’s key.
Unless a specific index is passed in, Pandas will simply generate an index for you by default. This index will start at the number 0 and go up to the length of the DataFrame minus 1. This type of index is called a RangeIndex (as it represents the values from the range function). However, if you’re working with specific data, such as time series data, you may want to index your data by another column.
Technically speaking, the data behind a Pandas Dataframe are backed by a hash table. This is similar to how Python dictionaries perform. Because of this, using an index to locate your data makes it significantly faster than searching across the entire column’s values.
Note: While indices technically exist across the DataFrame columns as well (i.e., along axis 1), when this article refers to an index, I’m only referring to the row index.
Loading a Sample Pandas Dataframe
To follow along with this tutorial, I have provided a sample Pandas DataFrame below. Feel free to copy the code below into your favorite text editor to follow along.
# Loading a Sample Pandas Dataframe
import pandas as pd
df = pd.DataFrame.from_dict({
'Name': ['Jane', 'Nik', 'Kate', 'Melissa'],
'Age': [10, 35, 34, 23],
'Height': [130, 178, 155, 133],
'Weight': [80, 200, 220, 150]
}).set_index('Name')
print(df)
# Returns:
# Age Height Weight
# Name
# Jane 10 130 80
# Nik 35 178 200
# Kate 34 155 220
# Melissa 23 133 150In the code block above, we used the .head() method to print out the first records of the DataFrame. We can see here that we now have a DataFrame that has an index of Name and three other columns. We used the .set_index() method to set the DataFrame index.
Now that we have a DataFrame to work with, let’s take a look at how we can use Pandas to drop an index column.
Dropping a Pandas Index Column Using reset_index
The most straightforward way to drop a Pandas DataFrame index is to use the Pandas .reset_index() method. By default, the method will only reset the index, creating a RangeIndex (from 0 to the length of the DataFrame minus 1). This technique will also insert the DataFrame index into a column in the DataFrame.
Let’s see what this looks like:
# Resetting a dataframe index with .reset_index()
df = df.reset_index()
print(df.head())
# Returns:
# Name Age Height Weight
# 0 Jane 10 130 80
# 1 Nik 35 178 200
# 2 Kate 34 155 220
# 3 Melissa 23 133 150
# 4 Evan 70 195 140We can see that the index column was replaced by a RangeIndex and the original columns were passed into the DataFrame as another column.
Dropping a Pandas Index Column and Deleting It
But what if we wanted to drop the DataFrame index and not keep it? We could then pass in the drop=True argument, instructing Pandas to reset the index and drop the original values. Let’s see what this looks like:
# Drop a Pandas Dataframe index with .reset_index() Method
df = df.reset_index(drop=True)
print(df.head())
# Returns:
# Age Height Weight
# 0 10 130 80
# 1 35 178 200
# 2 34 155 220
# 3 23 133 150
# 4 70 195 140We can see here that the DataFrame’s index is reset to the default behavior and that the original index is completely removed from the DataFrame.
Dropping a Pandas Index a Multi-Index DataFrame
Pandas also allows you to work with multi-index DataFrames, where the DataFrame has more than one column representing the index. This means that each record is represented by two or more unique identifiers. Let’s create a sample MultiIndex DataFrame:
# Creating a MultiIndex DataFrame
import pandas as pd
df = pd.DataFrame.from_dict({
'Gender': ['Female', 'Male', 'Female', 'Female'],
'Name': ['Jane', 'Nik', 'Kate', 'Melissa'],
'Age': [10, 35, 34, 23],
'Height': [130, 178, 155, 133],
'Weight': [80, 200, 220, 150]
}).set_index(['Gender', 'Name'])
print(df.head())
# Returns:
# Age Height Weight
# Gender Name
# Female Jane 10 130 80
# Male Nik 35 178 200
# Female Kate 34 155 220
# Melissa 23 133 150In order to drop both indices, you can simply call .reset_index(drop=True) method. However, if you only want to drop a single index, you must use the level= parameter. Let’s see how we can drop the 'Gender' index column, while retaining the values:
# Dropping a Single MultiIndex and Keeping Values
df = df.reset_index(level='Gender')
print(df)
# Returns:
# Gender Age Height Weight
# Name
# Jane Female 10 130 80
# Nik Male 35 178 200
# Kate Female 34 155 220
# Melissa Female 23 133 150In the code block above, we used the .reset_index() method where we specified dropping the Gender level. In this case, the index column was moved from the index values over to being column values.
Dropping a Pandas Index a Multi-Index DataFrame and Deleting Values
Similarly, when working with multi-index DataFrames we can drop just one index column and remove all of the values. In order to do this, we need to also pass in drop=True, as shown below:
# Dropping a Single MultiIndex and Dropping Values
import pandas as pd
df = pd.DataFrame.from_dict({
'Gender': ['Female', 'Male', 'Female', 'Female'],
'Name': ['Jane', 'Nik', 'Kate', 'Melissa'],
'Age': [10, 35, 34, 23],
'Height': [130, 178, 155, 133],
'Weight': [80, 200, 220, 150]
}).set_index(['Gender', 'Name'])
df = df.reset_index(level='Gender', drop=True)
print(df)
# Returns:
# Age Height Weight
# Name
# Jane 10 130 80
# Nik 35 178 200
# Kate 34 155 220
# Melissa 23 133 150We can see in the code block above that instead of inserting the column into the DataFrame, it is dropped and removed from the data. This can be helpful if a data isn’t needed and you want to reduce the complexity of the data.
In the next section, you’ll learn how to use the Pandas .set_index() method to drop a DataFrame’s index in Pandas.
Dropping a Pandas Index Column Using set_index
We can also drop an existing DataFrame index by overwriting it with new values using the .set_index() method.
We can also use a workaround of setting an index with a column that simply mirrors the normal index pattern. We can do this by first creating a column that contains the values from 0 through to the length of the list minus 1. We can do this directly using the .assign() method, which can be used to add a column to a Pandas DataFrame. We then use the .set_index() method to set that new column to the DataFrame’s index.
Let’s see what this looks like:
# Delete a Pandas Dataframe Index with .set_index()
df = df.assign(Index=range(len(df))).set_index('Index')
print(df.head())
# Returns:
# Age Height Weight
# 0 10 130 80
# 1 35 178 200
# 2 34 155 220
# 3 23 133 150
# 4 70 195 140What we’ve done here is first create a column called “Index” by using the .assign() method. We then chain in the .set_index() method to assign this new column to the index. This overwrites and deletes the former index.
In the next section, you’ll learn how to read a CSV file into a Pandas DataFrame without the implied index.
Read a CSV File into a Pandas DataFrame without an Index
You may encounter CSV files that are malformed, such as those that have a delimiter at the end of a given row. These may look like this:
Age,Height,Weight
10,130,80,
35,178,200,
34,155,220,
23,133,150,
70,195,140,
55,150,95,
89,205,180,Because there is a trailing comma, Pandas will incorrectly interpret the first values to be the index values. When we read the file into a DataFrame, it will look like this:
# Reading a malformed .csv file with Pandas
df = pd.read_csv('file.csv')
print(df.head())
# Returns:
# Age Height Weight
# 10 130 80 NaN
# 35 178 200 NaN
# 34 155 220 NaN
# 23 133 150 NaN
# 70 195 140 NaNOf course, this is not what we want. We would want the data to be properly aligned with the columns so that an empty column is returned at the end. Because these files can often be found, Pandas introduced a parameter that allows us to overwrite the default behavior, when using the read_csv function.
Let’s see what happens when we pass in index_col = False into our function:
# Reading a malformed CSV file correctly with Pandas
df = pd.read_csv('file.csv', index_col=False)
print(df.head())
# Returns:
# Age Height Weight
# 0 10 130 80
# 1 35 178 200
# 2 34 155 220
# 3 23 133 150
# 4 70 195 140We can see that by using the index_col=False argument, that Pandas overwrites the default behavior and assigns a proper index.
Conclusion
In this tutorial, you learned how to use Pandas to drop an index column. You learned how to use the Pandas .reset_index() and .set_index() methods to drop an index. You also learned how both read and write a CSV file to a Pandas DataFrame. Being able to work with Pandas indices is a useful skill as you learn how to manipulate data using Pandas.
To learn more about the Pandas .reset_index() method, check out the official documentation here.
Additional Resources
To learn more about similar topics, check out some of these related articles:
I want to seek python language.
You’re in the right place!
Thanks for the informations! saved my day right there!
Thank you so much, Islam!