
In this tutorial, you’ll learn how to shuffle a Pandas Dataframe rows using Python. You’ll learn how to shuffle your Pandas Dataframe using Pandas’ sample method, sklearn’s shuffle method, as well as Numpy’s permutation method. You’ll also learn why it’s often a good idea to shuffle your data, as well as how to shuffle your data and be able to recreate your results. Finally, you’ll learn which of the methods is the fastest method.
Being able to shuffle a Pandas Dataframe is a task you’ll often want to take on prior to performing any type of machine learning model training. Because our data is often sorted in a particular way (say, for example, by date or by geographical area), we want to make sure that our data is representative. Because of this, we will want to shuffle our Pandas dataframe prior to taking on any modelling.
Because our machine learning models will often be based on a smaller sample of our data, we want to make sure that the data that we select is representative of the true distribution of our data.
The Quick Answer: Use Pandas’ .sample Method to Shuffle Your Dataframe
df.sample()Table of Contents
Loading a Sample Pandas Dataframe
In the code block below, you’ll find some Python code to generate a sample Pandas Dataframe. If you want to follow along with this tutorial line-by-line, feel free to copy the code below in order. You can also use your own dataframe, but your results will, of course, vary from the ones in the tutorial.
# Loading a Sample Pandas Dataframe
import pandas as pd
df = pd.DataFrame.from_dict({
'Name': ['Nik', 'Kate', 'Kevin', 'Evan', 'Jane', 'Kyra', 'Melissa'],
'Gender': ['Male', 'Female', 'Male', 'Male', 'Female', 'Female', 'Female'],
'January': [90, 95, 75, 93, 60, 85, 75],
'February': [95, 95, 75, 65, 50, 85, 100],
})
print(df.head())
# Returns:
# Name Gender January February
# 0 Nik Male 90 95
# 1 Kate Female 95 95
# 2 Kevin Male 75 75
# 3 Evan Male 93 65
# 4 Jane Female 60 50We can see that our dataframe has four columns: two containing strings and two containing numeric values.
Shuffle a Pandas Dataframe with sample
One of the easiest ways to shuffle a Pandas Dataframe is to use the Pandas sample method. The df.sample method allows you to sample a number of rows in a Pandas Dataframe in a random order. Because of this, we can simply specify that we want to return the entire Pandas Dataframe, in a random order.
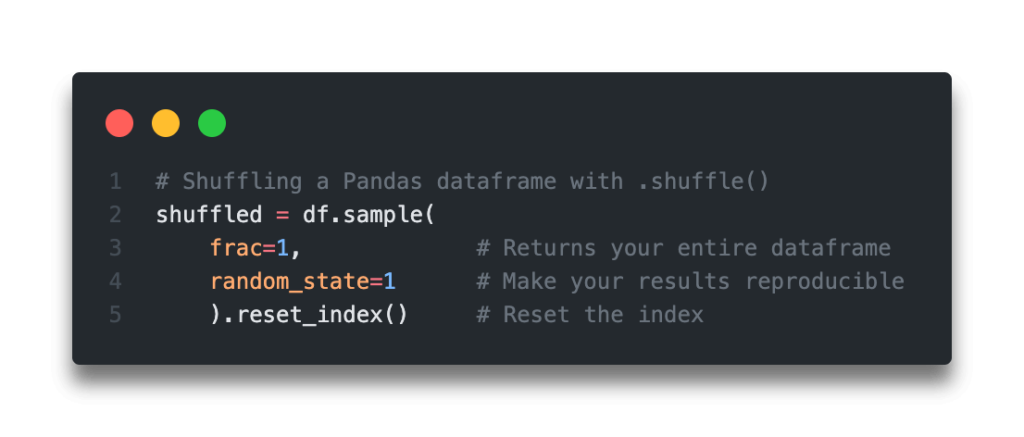
In order to do this, we apply the sample method to our dataframe and tell the method to return the entire dataframe by passing in frac=1. This instructs Pandas to return 100% of the dataframe.
Let’s try this out in Pandas:
# Shuffling a Pandas dataframe with .shuffle()
shuffled = df.sample(frac=1)
print(shuffled)
# Returns:
# Name Gender January February
# 0 Nik Male 90 95
# 2 Kevin Male 75 75
# 6 Melissa Female 75 100
# 1 Kate Female 95 95
# 3 Evan Male 93 65
# 4 Jane Female 60 50
# 5 Kyra Female 85 85We can see that by applying the .sample() method, that the dataframe was shuffled in a random order. We can see, however, that our original index values are maintained. We can reset our index using the Pandas .reset_index() method, which resets our index to be sorted from 0 onwards. Let’s see what this looks like:
# Shuffling a Pandas dataframe with .shuffle()
shuffled = df.sample(frac=1).reset_index()
print(shuffled.head())
# Returns:
# Name Gender January February
# 0 Nik Male 90 95
# 1 Kevin Male 75 75
# 2 Melissa Female 75 100
# 3 Kate Female 95 95
# 4 Evan Male 93 65In the next section, you’ll learn how to shuffle a Pandas Dataframe using sample, while being able to reproduce your results.
Reproduce Your Shuffled Pandas Dataframe
One of the important aspects of data science is the ability to reproduce your results. When you apply the sample method to a dataframe, it returns a newly shuffled dataframe each time.
We’re able to reproduce our results by passing a value into the random_state= argument. We can simply pass in an integer value and the shuffled dataframe will look the same each time.
Why use random_state? Being able to reproduce your results is a helpful skill in machine learning in order to better be able to understand your workflow. This can be particularly helpful when others are reviewing and reproduce your results. It’s also very helpful in being able to properly troubleshoot your code.
Let’s see how this works:
# Reproducing a shuffled dataframe in Pandas with random_state=
shuffled = df.sample(frac=1, random_state=1).reset_index()
print(shuffled.head())
# Returns:
# index Name Gender January February
# 0 6 Melissa Female 75 100
# 1 2 Kevin Male 75 75
# 2 1 Kate Female 95 95
# 3 0 Nik Male 90 95
# 4 4 Jane Female 60 50When we rerun this code, we now get the same result each time.
Shuffle a Pandas Dataframe with Sci-Kit Learn’s shuffle
Another helpful way to randomize a Pandas Dataframe is to use the machine learning library, sklearn. One of the main benefits of this approach is that you can build it easily into your sklearn pipelines, allowing you to generate simple flows of data.
Sklearn comes with a method, shuffle, that we can apply to our dataframe. Let’s see what this looks like:
# Shuffling a Pandas dataframe with sklearn
from sklearn.utils import shuffle
shuffled = shuffle(df)
print(shuffled.head())
# Returns:
# Name Gender January February
# 5 Kyra Female 85 85
# 1 Kate Female 95 95
# 4 Jane Female 60 50
# 0 Nik Male 90 95
# 6 Melissa Female 75 100Similar to using the Pandas .sample method, if we wanted to be able to reproduce our results, we can use the random_state= parameter. Let’s see what this looks like:
# Shuffling a Pandas dataframe with sklearn
from sklearn.utils import shuffle
shuffled = shuffle(df, random_state=1)
print(shuffled.head())
# Returns:
# Name Gender January February
# 6 Melissa Female 75 100
# 2 Kevin Male 75 75
# 1 Kate Female 95 95
# 0 Nik Male 90 95
# 4 Jane Female 60 50In the final section below, you’ll learn how to use the numpy library to randomize your Pandas dataframe.
Shuffle a Pandas Dataframe with Numpy’s random.permutation
In this final section, you’ll learn how to use NumPy to randomize a Pandas dataframe. Numpy comes with a function, random.permutation(), that allows us to generate a random permutation of an array.
In order to shuffle our dataframe, we can pass our dataframe’s indices into the function, which randomizes their order. We then use the .iloc accessor to reorder our data. Let’s see what this looks like:
# Shuffling a Pandas dataframe with numpy
from numpy.random import permutation
shuffled = df.iloc[permutation(df.index)]
print(shuffled.head())
# Returns:
# Name Gender January February
# 5 Kyra Female 85 85
# 2 Kevin Male 75 75
# 3 Evan Male 93 65
# 6 Melissa Female 75 100
# 0 Nik Male 90 95The Fastest Way to Shuffle a Pandas Dataframe
You may be wondering, at this point, which method to choose. I would recommend looking at which method fits best into your workflow. For example, if you’re building a data science pipeline with sklearn, you may want to build the shuffling into your pipeline using the sklearn shuffle utility.
Another big consideration can be speed – which method will yield the fastest results time after time.
In order to produce the results below, we shuffled a Pandas Dataframe containing 1,500,00 records a thousand times. The average of each run was calculated, producing a reliable result:
| Method | Time for Execution |
|---|---|
df.sample() | 18.3 µs ± 255 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) |
np.utils.permutation() | 17.9 µs ± 122 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) |
sklearn.utils.shuffle() | 17.9 µs ± 5.53 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) |
We can see that the results are quite close! Unless optimal speed is your ultimate goal, you can safely choose any method. That being said, you’ll be import Pandas regardless. Importing packages you’re not using can add additional speed considerations to your script.
Conclusion
In this tutorial, you learned how to shuffle a Pandas Dataframe using the Pandas sample method. The method allows us to sample rows in a random order. In order to shuffle our dataframe, we simply sample the entire dataframe. We’re even able to reproduce our shuffle dataframe using the random_state= parameter.
You also learned how to use the sklearn and numpy libraries to shuffle your dataframe, giving you even more flexibility in terms of how you produce your results. For example, using sklearn provides you with the opportunity to easily integrate this step into machine learning pipelines.
To learn more about the methods covered off in this tutorial, check out the official documentation found here:
- Pandas
.sample()documentation - Numpy
random.permutation()documentation - Sklearn
shuffle()documentation
Related Articles
To learn more about related content, check out the following articles:
Pingback: Splitting Your Dataset with Scitkit-Learn train_test_split • datagy