
In this tutorial, you’ll learn how to calculate a weighted average using Pandas and Python. Weighted averages take into account the “weights” of a given value, meaning that they can be more representative of the actual average. This serves many practical applications, including calculating sales projections or better performance over different periods of time.
While Pandas comes with a number of helpful functions built-in, such as an incredibly easy way to calculate an average of a column, there is no built-in way to calculate the weighted average. In itself, this isn’t an issue as Pandas makes it relatively easy to define a function to accomplish this.
By the end of this tutorial, you’ll have learned what the weighted average is and how it differs from the normal arithmetic mean, how to calculate the weighted average of a Pandas column, and how to calculate it based on two different lists.
The Quick Answer: Use Pandas .groupby()
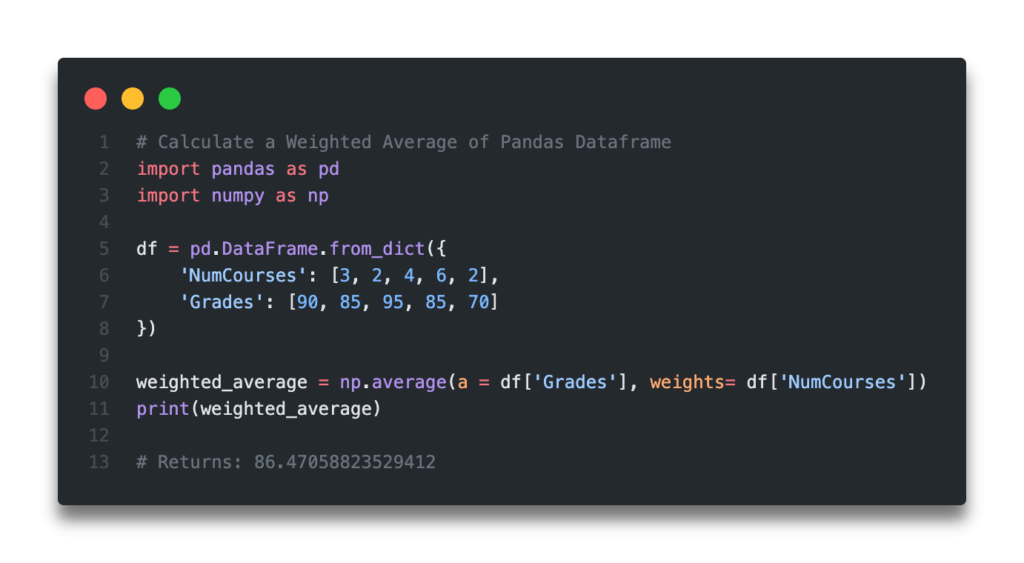
Table of Contents
What is a Weighted Average?
The term weighted average refers to an average that takes into account the varying degrees of importance of the numbers in the dataset. Because of this, the weighted average will likely be different from the value you calculate using the arithmetic mean.
The formula for the weighted average looks like this:

What this formula represents is the sum of each item times its weight, divided by the number of items.
Let’s see how this compares with some sample data. Let’s look at the following table, where we want to calculate the average grade per course.
| Number of Courses | Grade |
|---|---|
| 3 | 90 |
| 2 | 85 |
| 4 | 95 |
| 6 | 85 |
| 2 | 70 |
If we were to calculate the regular average, you may calculate it as such:
( 90 + 85 + 95 + 85 + 70 ) / 5
This, however, may present some problems giving the differences in number of courses. If we really wanted to calculate the average grade per course, we may want to calculate the weighted average.
This calculation would look like this:
( 90×3 + 85×2 + 95×4 + 85×4 + 70×2 ) / (3 + 2 + 4 + 6 + 2 )
This can give us a much more representative grade per course.
Let’s see how we can develop a custom function to calculate the weighted average in Pandas.
Want to learn more about Python for-loops? Check out my in-depth tutorial that takes your from beginner to advanced for-loops user! Want to watch a video instead? Check out my YouTube tutorial here.
Calculate a Weighted Average in Pandas Using a Custom Function
In this section, you’ll learn how to use Python to create a custom function to calculate the weighted average of a Pandas Dataframe. While Pandas comes with a built-in mean() method, we’ll need to develop a custom function. This is because the weighted average actually depends on multiple variables: one that defines the weight and another that holds the actual values.
Let’s load our sample table from above as a dataframe that we can use throughout the tutorial:
# Calculate a Pandas Weighted Average Using a Custom Function
import pandas as pd
df = pd.DataFrame.from_dict({
'NumCourses': [3, 2, 4, 6, 2],
'Grades': [90, 85, 95, 85, 70]
})
print(df)
# Returns:
# NumCourses Grades
# 0 3 90
# 1 2 85
# 2 4 95
# 3 6 85
# 4 2 70We can develop a custom function that calculates a weighted average by passing in two arguments: a column that holds our weights and a column that holds our grades.
Let’s see what this calculation looks like:
# Calculate a Pandas Weighted Average Using a Custom Function
import pandas as pd
df = pd.DataFrame.from_dict({
'NumCourses': [3, 2, 4, 6, 2],
'Grades': [90, 85, 95, 85, 70]
})
def weighted_average(df, values, weights):
return sum(df[weights] * df[values]) / df[weights].sum()
print(weighted_average(df, 'Grades', 'NumCourses'))
# Returns: 86.47058823529412Let’s break down what we’ve done here:
- We created a function that accepts a dataframe and two columns as input: one that provides the values and another that provides the weights
- We then input the formula which calculates the sum of the weights multiplied by the values, divided by the sum of the values
In the next section, you’ll learn how to use a groupby() method to calculate a weighted average in Pandas.
Calculate a Weighted Average in Pandas Using GroupBy
There may be times when you have a third variable by which you want to break up your data. Say that, for example, our data is broken up by year as well. We then want to calculate the weighted average by year. That’s where the .groupby() method comes into play.
Let’s add the Year column to our dataframe and see how we can calculate a weight average for each year:
# Calculate a Pandas Weighted Average Using GroupBy
import pandas as pd
df = pd.DataFrame.from_dict({
'Year': ['2021', '2021', '2022', '2022', '2022'],
'NumCourses': [3, 2, 4, 6, 2],
'Grades': [90, 85, 95, 85, 70]
})
def weighted_average(df, values, weights):
return sum(df[weights] * df[values]) / df[weights].sum()
print(df.groupby('Year').apply(weighted_average, 'Grades', 'NumCourses'))
# Returns:
# Year
# 2021 88.000000
# 2022 85.833333
# dtype: float64Here, we first use the .groupby() method to group our data by Year. Then we apply the function and pass in the two columns. This returns a printed series of data.
In the next section, you’ll learn how to use numpy to create a weighted average.
Calculate a Weighted Average in Pandas Using Numpy
The numpy library has a function, average(), which allows us to pass in an optional argument to specify weights of values. The function will take an array into the argument a=, and another array for weights under the argument weights=.
Let’s see how we can calculate the weighted average of a Pandas Dataframe using numpy:
# Calculate a Pandas Weighted Average Using Numpy
import pandas as pd
import numpy as np
df = pd.DataFrame.from_dict({
'NumCourses': [3, 2, 4, 6, 2],
'Grades': [90, 85, 95, 85, 70]
})
weighted_average = np.average(a=df['Grades'], weights=df['NumCourses'])
print(weighted_average)
# Returns: 86.47058823529412This is a much cleaner way of calculating the weighted average of a Pandas Dataframe. It’s important to consider readability when writing code – you want your code to be intuitive. If that involves importing another function from a module, then that may be worth the trade-off.
In the next section, you’ll learn how to calculate a weighted average of two lists using Python’s zip function.
Calculate a Weighted Average of Two Lists Using Zip
In this section, you’ll learn how to calculate a weighted average of two lists, using the Python zip function. While this method may not be as practical as using any of the other methods described above, it may come in handy during programming interviews.
Let’s say you’re given two lists: one that contains weights and one that contains the actual values.
We can calculate the weighted average of the values list using the following approach:
# Calculate a Weighted Average of Two Lists in Python
num_courses = [3, 2, 4, 6, 2]
grades = [90, 85, 95, 85, 70]
def weighted_average(values, weights):
weighted_sum = []
for value, weight in zip(values, weights):
weighted_sum.append(value * weight)
return sum(weighted_sum) / sum(weights)
print(weighted_average(grades, num_courses))
# Returns: 86.47058823529412In the example above, we developed a new function that accepts two lists as its parameters. The function instantiates a new list, then loops over the zip object returned from the two lists. The values are multiplied and added up, then divided by the sum of the weights.
Want to learn how to use the Python zip() function to iterate over two lists? This tutorial teaches you exactly what the zip() function does and shows you some creative ways to use the function.
Conclusion
In this tutorial, you learned how to calculate a weighted average in Pandas, including how to use Pandas, a custom function, numpy, and the zip function. Being able to calculate a weighted average has many practical applications, including in business and science.
To learn more about the numpy average function, check out the official documentation here.