
The Pandas get dummies function, pd.get_dummies(), allows you to easily one-hot encode your categorical data. In this tutorial, you’ll learn how to use the Pandas get_dummies function works and how to customize it. One-hot encoding is a common preprocessing step for categorical data in machine learning.
If you’re looking to integrate one-hot encoding into your scikit-learn workflow, you may want to consider the OneHotEncoder class from scikit-learn!
By the end of this tutorial, you’ll have learned:
- What one-hot encoding is and why to use it
- How to use the Pandas
get_dummies()function to one-hot encode data - How to one-hot encode multiple columns with Pandas
get_dummies() - How to customize the output of one-hot encoded columns in Pandas
- How to work with missing data when one-hot encoding with Pandas
Table of Contents
Understanding One-Hot Encoding in Machine Learning
One-hot encoding is an important step for preparing your dataset for use in machine learning. One-hot encoding turns your categorical data into a binary vector representation. Pandas get dummies makes this very easy!
This is important when working with many machine learning algorithms, such as decision trees and support vector machines, which accept only numeric inputs.
This means that for each unique value in a column, a new column is created. The values in this column are represented as 1s and 0s, depending on whether the value matches the column header.
See the image below for a visual representation of what happens:
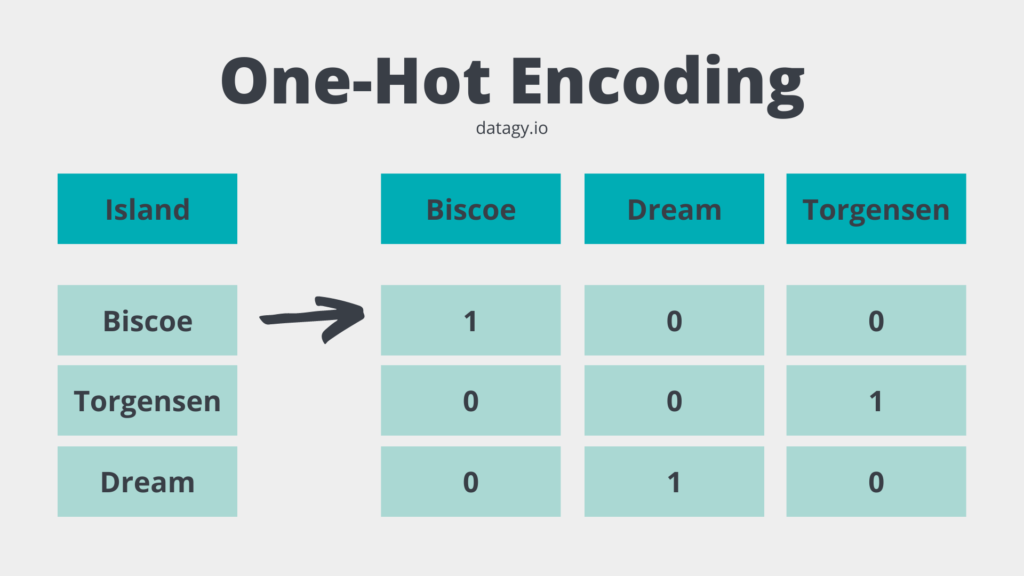
You may be wondering why we didn’t simply turn the values in the column to, say, {'Biscoe': 1, 'Torgensen': 2, 'Dream': 3}. This would presume a larger difference between Biscoe and Dream than between Biscoe and Torgensen.
While this difference may exist, it isn’t specified in the data and shouldn’t be imagined.
However, if your data is ordinal, meaning that the order matters, then this approach may be appropriate. For example, when comparing shirt sizes, the difference between a Small and a Large is, in fact, bigger than between a Medium and a Large.
What are some potential drawbacks of one-hot encoding?
One hot-encoding can be very helpful in terms of working with categorical variables. One major drawback, however, is that it creates significantly more data. Because of this, it shouldn’t be used when there are too many categories.
Loading a Sample Dataset
Let’s begin this tutorial by loading our required libraries and creating a dataset we can use throughout the tutorial. If you have your own dataset to follow along with, feel free to skip the step below.
# Loading a Sample DataFrame
import pandas as pd
df = pd.DataFrame({
'Name': ['Joan', 'Matt', 'Jeff', 'Melissa', 'Devi'],
'Gender': ['Female', 'Male', 'Male', 'Female', 'Female'],
'House Type': ['Apartment', 'Detached', 'Apartment', None, 'Semi-Detached']
})
print(df)
# Returns:
# Name Gender House Type
# 0 Joan Female Apartment
# 1 Matt Male Detached
# 2 Jeff Male Apartment
# 3 Melissa Female None
# 4 Devi Female Semi-DetachedIn the code above, we loaded a DataFrame with three columns, Name, Gender, and House Type. Both the Gender and House Type columns represent categorical data. Now that we have our DataFrame loaded, let’s take a look at the pd.get_dummies() function.
Understanding the Pandas get_dummies Function
Before diving into using the Pandas get_dummies() function, it’s important to first understand the syntax of the function. This allows you to better understand what output to expect and how to customize the function to meet your needs.
Let’s take a look at what makes up the pd.get_dummies() function:
# Understanding the Pandas get_dummies function
import pandas as pd
pd.get_dummies(
data,
prefix=None,
prefix_sep='_',
dummy_na=False,
columns=None,
sparse=False,
drop_first=False,
dtype=None
)We can see that the function offers a large number of parameters! Let’s take a look at what each of these parameters accomplishes:
data=represents the data from which to get the dummy indicators (either array-like, Pandas Series, or Pandas DataFrame)prefix=represents the string to append to DataFrame column namesprefix_sep=represents what delimiter to usedummy_na=represents whether to add a column or not for missing valuescolumns=represents the names of the columns to be encodedsparse=represents whether the data should be a sparse array or a regular NumPy arraydrop_first=represents whether to drop the first level or notdtype=represents the data type for new columns
Now that you have a strong understanding of the parameters available in the pd.get_dummies() function, let’s see how you can use the function to one-hot encode your data.
How to use the Pandas get_dummies function
In the previous section, you learned how to understand the parameters available in the pd.get_dummies() function. In this section, you’ll learn how to one-hot encode your data. The only required parameter is the data= parameter, which accepts either a Pandas Series or DataFrame.
Let’s see what happens when we pass in a single column into the data= parameter:
# One-Hot Encoding a Single DataFrame Series
import pandas as pd
df = pd.DataFrame({
'Name': ['Joan', 'Matt', 'Jeff', 'Melissa', 'Devi'],
'Gender': ['Female', 'Male', 'Male', 'Female', 'Female'],
'House Type': ['Apartment', 'Detached', 'Apartment', None, 'Semi-Detached']
})
print(pd.get_dummies(df['Gender']))
# Returns:
# Female Male
# 0 1 0
# 1 0 1
# 2 0 1
# 3 1 0
# 4 1 0We can see that by calling this function, we return a DataFrame. This is really helpful, but it, unfortunately, doesn’t include the other columns.
Let’s see how we can pass in a DataFrame as our data= parameter and one-hot encode a single column:
# One-Hot Encoding and Returning a DataFrame
import pandas as pd
df = pd.DataFrame({
'Name': ['Joan', 'Matt', 'Jeff', 'Melissa', 'Devi'],
'Gender': ['Female', 'Male', 'Male', 'Female', 'Female'],
'House Type': ['Apartment', 'Detached', 'Apartment', None, 'Semi-Detached']
})
ohe = pd.get_dummies(data=df, columns=['Gender'])
print(ohe)
# Returns:
# Name House Type Gender_Female Gender_Male
# 0 Joan Apartment 1 0
# 1 Matt Detached 0 1
# 2 Jeff Apartment 0 1
# 3 Melissa None 1 0
# 4 Devi Semi-Detached 1 0We can see that this returns the original DataFrame with the Gender column one-hot encoded.
Working with Missing Data in Pandas get_dummies
In this section, you’ll learn how to work with missing data when one-hot encoding data using the Pandas get_dummies() function. By default, many machine learning models can’t work with missing data. This means that you can either drop or impute the missing records.
This is true for one-hot encoding as well – the Pandas get_dummies() function will ignore any missing values. Let’s see what this looks like by one-hot encoding the House Type column:
# One-Hot Encoding a Column with Missing Data
import pandas as pd
df = pd.DataFrame({
'Name': ['Joan', 'Matt', 'Jeff', 'Melissa', 'Devi'],
'Gender': ['Female', 'Male', 'Male', 'Female', 'Female'],
'House Type': ['Apartment', 'Detached', 'Apartment', None, 'Semi-Detached']
})
ohe = pd.get_dummies(df['House Type'])
print(ohe)
# Returns:
# Apartment Detached Semi-Detached
# 0 1 0 0
# 1 0 1 0
# 2 1 0 0
# 3 0 0 0
# 4 0 0 1In the code block above, we one-hot encoded the House Type column, which included a missing record in index position 3. We can see that none of the one-hot encoded columns carry a value for this record.
We can modify this behavior by one-hot encoding missing values using the dummy_na= parameter, which has a default argument of False. Let’s set this argument to True and see how this modifies the output:
# One-Hot Encoding Columns with Missing Data
import pandas as pd
df = pd.DataFrame({
'Name': ['Joan', 'Matt', 'Jeff', 'Melissa', 'Devi'],
'Gender': ['Female', 'Male', 'Male', 'Female', 'Female'],
'House Type': ['Apartment', 'Detached', 'Apartment', None, 'Semi-Detached']
})
ohe = pd.get_dummies(df['House Type'], dummy_na=True)
print(ohe)
# Returns:
# Apartment Detached Semi-Detached NaN
# 0 1 0 0 0
# 1 0 1 0 0
# 2 1 0 0 0
# 3 0 0 0 1
# 4 0 0 1 0We can see here that this includes a new column for missing data in that column.
One-Hot Encoding Multiple Columns with Pandas get_dummies
In this section, you’ll learn how to one-hot encode multiple columns with the Pandas get_dummies() function. In many cases, you’ll need to one-hot encode multiple columns and Pandas makes this very easy to do.
By passing a DataFrame into the data= parameter and passing in a list of columns into the columns= parameter, you can easily one-hot encode multiple columns. Let’s see what this looks like:
# One-Hot Encoding Multiple Columns with Pandas get_dummies()
import pandas as pd
df = pd.DataFrame({
'Name': ['Joan', 'Matt', 'Jeff', 'Melissa', 'Devi'],
'Gender': ['Female', 'Male', 'Male', 'Female', 'Female'],
'House Type': ['Apartment', 'Detached', 'Apartment', None, 'Semi-Detached']
})
ohe = pd.get_dummies(data=df, columns=['Gender', 'House Type'])
print(ohe)
# Returns:
# Name Gender_Female Gender_Male House Type_Apartment House Type_Detached House Type_Semi-Detached
# 0 Joan 1 0 1 0 0
# 1 Matt 0 1 0 1 0
# 2 Jeff 0 1 1 0 0
# 3 Melissa 1 0 0 0 0
# 4 Devi 1 0 0 0 1We can see how easy it is to one-hot encode multiple columns using the Pandas get_dummies() function.
Modifying the Column Separator in Pandas get_dummies
Pandas also makes it very easy to modify the separator used when one-hot encoding columns. By default, Pandas will use an underscore character to separate the prefix from the encoded variable. This can be done using the prefix_sep=
In the example above, we saw that the 'House Type' column contained a space. The default separator, then, looks a little awkward. Let’s change the separator to be a space:
# Changing the Prefix Separator in Pandas get_dummies()
import pandas as pd
df = pd.DataFrame({
'Name': ['Joan', 'Matt', 'Jeff', 'Melissa', 'Devi'],
'Gender': ['Female', 'Male', 'Male', 'Female', 'Female'],
'House Type': ['Apartment', 'Detached', 'Apartment', None, 'Semi-Detached']
})
ohe = pd.get_dummies(data=df, columns=['House Type'], prefix_sep=' ')
print(ohe)
# Returns:
# Name Gender House Type Apartment House Type Detached House Type Semi-Detached
# 0 Joan Female 1 0 0
# 1 Matt Male 0 1 0
# 2 Jeff Male 1 0 0
# 3 Melissa Female 0 0 0
# 4 Devi Female 0 0 1Conclusion
In this tutorial, you learned how one-hot encode data using the Pandas get_dummies() function. First, you learned what one-hot encoding is and how it’s used in machine learning. Then, you learned how to use the Pandas get_dummies() function to one-hot encode data. You learned how to insert the encoded columns directly into a DataFrame, work with multiple columns and with missing data.
Frequently Asked Questions
While both functions one-hot encode your DataFrame columns, the Scikit-Learn OneHotEncoder class can be integrated into Scikit-Learn workflows, including pipelines and other transformations.
One-hot encoding converts a column into n variables, while dummy encoding creates n-1 variables. However, Pandas by default will one-hot encode your data. This can be modified by using the drop_first parameter.
Additional Resources
To learn more about related topics, check out the tutorials below:
Pingback: Introduction to Random Forests in Scikit-Learn (sklearn) • datagy
Pingback: Linear Regression in Scikit-Learn (sklearn): An Introduction • datagy
thank you for good view .
The same result from one line of code:
df = pd.get_dummies(df, columns = categorical_columns, prefix=categorical_columns, drop_first=True)
You can add the drop_first argument to remove the first categorical level.
Ah, that’s a great tip! Thanks Gee!