
In this tutorial, you’ll learn how to use Python to remove duplicates from a list. Knowing how to working with Python lists is an important skill for any Pythonista. Being able to remove duplicates can be very helpful when working with data where knowing frequencies of items is not important.
You’ll learn how to remove duplicates from a Python list while maintaining order or when order doesn’t matter. You’ll learn how to do this using naive methods, list comprehensions, sets, dictionaries, the collections library, numpy, and pandas.
The Quick Answer:
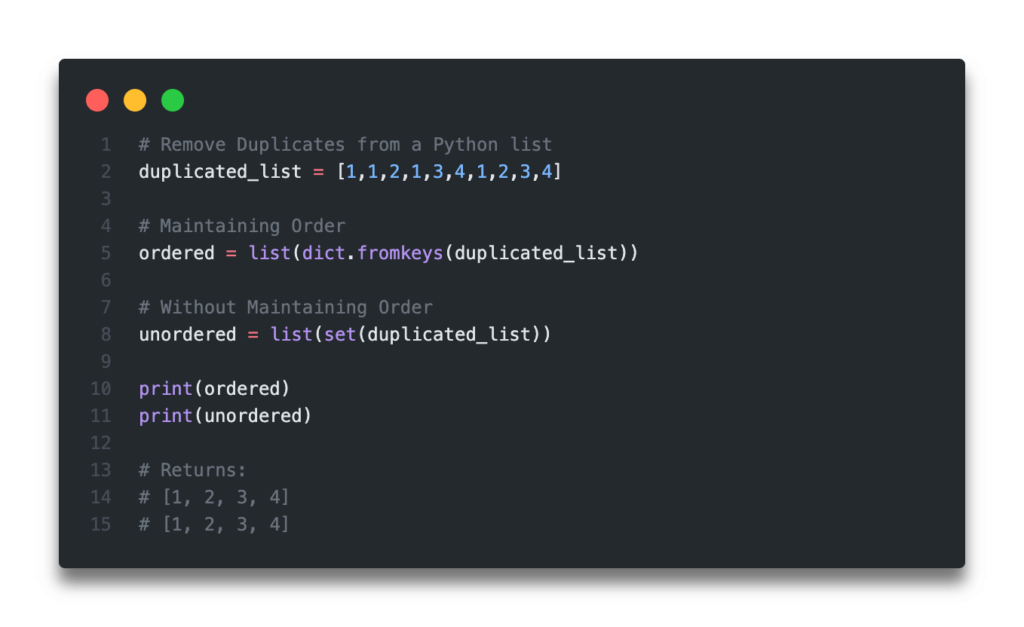
Table of Contents
Remove Duplicates from a Python List Using For Loops
The most naive implementation of removing duplicates from a Python list is to use a for loop method. Using this method involves looping over each item in a list and seeing if it already exists in another list.
Let’s see what this looks like in Python:
# Remove Duplicates from a Python list using a For Loop
duplicated_list = [1,1,2,1,3,4,1,2,3,4]
deduplicated_list = list()
for item in duplicated_list:
if item not in deduplicated_list:
deduplicated_list.append(item)
print(deduplicated_list)Let’s explore what we did here:
- We instantiated a new, empty list to hold de-duplicated items
- We looped over each item in our duplicated list and checked if it existed in the deduplicated list
- If it didn’t, we appended the item to our list. If it did exist, then we did nothing
In the next section, you’ll learn how to deduplicate a list in Python using a list comprehension.
Want to learn more about Python for-loops? Check out my in-depth tutorial that takes your from beginner to advanced for-loops user! Want to watch a video instead? Check out my YouTube tutorial here.
Remove Duplicates from a Python List Using a List Comprehension
Similar to the method using for loops, you can also use Python list comprehensions to deduplicate a list. The process involved here is a little different than a normal list comprehension, as we’ll be using the comprehension more for looping over the list.
Let’s see what this looks like:
# Remove Duplicates from a Python list using a List Comprehension
duplicated_list = [1,1,2,1,3,4,1,2,3,4]
deduplicated_list = list()
[deduplicated_list.append(item) for item in duplicated_list if item not in deduplicated_list]
print(deduplicated_list)This approach is a little bit awkward as the list comprehension sits by itself. This can make the code less intuitive to follow, as list comprehensions are often used to create new lists. However, since we’re only looping over the list and appending to another list, no new list is instantiated using the comprehension.
In the next section, you’ll learn how to use Python dictionaries to deduplicate a Python list.
Want to learn more about Python list comprehensions? Check out this in-depth tutorial that covers off everything you need to know, with hands-on examples. More of a visual learner, check out my YouTube tutorial here.
Use Python Dictionaries to Remove Duplicates from a List
Since Python 3.7, Python dictionaries maintain the original order of items passed into them. While this method will work for versions earlier than Python 3.7, the resulting deduplicated list will not maintain the order of the original list.
The reason that converting a list to a dictionary works is that dictionary keys must be unique. One important thing to note is that Python dictionaries require their keys to be hashable, meaning that they must be immutable. if your list contains mutable elements, then this approach will not work.
Let’s take a look at how we can use Python dictionaries to deduplicate a list:
# Remove Duplicates from a Python list using a dictionary
duplicated_list = [1,1,2,1,3,4,1,2,3,4]
dictionary = dict.fromkeys(duplicated_list)
deduplicated_list = list(dictionary)
print(deduplicated_list)
# Returns: [1, 2, 3, 4]Let’s take a look at what we’ve done here:
- We created a dictionary using the
.fromkeys()method, which uses the items passed into it to create a dictionary with the keys from the object - We then turned the dictionary into a list using the
list()function, which creates a list from the keys in the dictionary.
In the next section, you’ll learn how to use Python sets to deduplicate a list.
Need to check if a key exists in a Python dictionary? Check out this tutorial, which teaches you five different ways of seeing if a key exists in a Python dictionary, including how to return a default value.
Use Python Sets to Remove Duplicates from a List
Sets are unique Python data structures that are generated using the curly braces {}. They contain only unique items and are unordered and unindexed.
Because Python sets are unique, when we create a set based off of another object, such as a list, then duplicate items are removed.
What we can do is first convert our list to a set, then back to a list.
Let’s see what this looks like in Python:
# Remove Duplicates from a Python list using a set()
duplicated_list = [1,1,2,1,3,4,1,2,3,4]
deduplicated_list = list(set(duplicated_list))
print(deduplicated_list)
# Returns: [1, 2, 3, 4]What we did here was:
- We passed our original list into the
set()function, which created a set and removed all duplicate items, - We then passed that set into the
list()function, to produce another list
In the next section, you’ll learn how to use the collections library to remove duplicates from a Python list.
Want to learn how to use the Python zip() function to iterate over two lists? This tutorial teaches you exactly what the zip() function does and shows you some creative ways to use the function.
Remove Duplicates from a Python List Using Collections
If you’re working with an older version of Python that doesn’t support ordered dictionaries (prior to Python 3.6), you can also use the collections library to accomplish a very similar approach.
We use the collections library to create an ordered dictionary and then convert it back to a list.
Let’s see how this works:
# Remove Duplicates from a Python list using a collections
from collections import OrderedDict
duplicated_list = [1,1,2,1,3,4,1,2,3,4]
deduplicated_list = list(OrderedDict.fromkeys(duplicated_list))
print(deduplicated_list)
# Returns: [1, 2, 3, 4]In the next section, you’ll learn how to use numpy to remove duplicates from a list.
Check out some other Python tutorials on datagy, including our complete guide to styling Pandas and our comprehensive overview of Pivot Tables in Pandas!
Use Numpy to Remove Duplicates from a Python List
The popular Python library numpy has a list-like object called arrays. What’s great about these arrays is that they have a number of helpful methods built into them.
One of these functions is the unique() function, which finds, well, unique items in an array.
Let’s see how we can use numpy to remove duplicates from a Python list.
# Remove Duplicates from a Python list using a numpy array
import numpy as np
duplicated_list = [1,1,2,1,3,4,1,2,3,4]
deduplicated_list = np.unique(np.array(duplicated_list)).tolist()
print(deduplicated_list)
# Returns: [1, 2, 3, 4]Here, we first create an array out of our list, pass it into the unique() function. Finally, we use the .tolist() method to create a list out of the array.
In the final section, you’ll learn how to use Pandas to deduplicate a Python list.
Want to learn more about calculating the square root in Python? Check out my tutorial here, which will teach you different ways of calculating the square root, both without Python functions and with the help of functions.
Use Pandas to Remove Duplicates from a Python List
In this final section, you’ll learn how to use the popular pandas library to de-duplicate a Python list.
Pandas uses a numpy array and creates a Pandas series object. These objects are also similar to Python lists, but are extended by a number of functions and methods that can be applied to them.
Let’s see how we can do this in Python and Pandas:
# Remove Duplicates from a Python list using Pandas
import pandas as pd
duplicated_list = [1,1,2,1,3,4,1,2,3,4]
deduplicated_list = pd.Series(duplicated_list).unique().tolist()
print(deduplicated_list)
# Returns: [1, 2, 3, 4]In this, we first created a pd.Series() object, then apply the .unique() method, and finally use the .tolist() method to return a list.
Need to automate renaming files? Check out this in-depth guide on using pathlib to rename files. More of a visual learner, the entire tutorial is also available as a video in the post!
Conclusion
In this tutorial, you learned a number of different ways to remove duplicates from a Python list. You learned a number of naive methods of doing this, including using for loops and list comprehensions. You also learned how to use sets and dictionaries to remove duplicates, as well as using other libraries, such as collections, numpy, and pandas to do this.
To learn more about the collections library, check out the official documentation here.
Hey,
the list comprehension is not correct over here. If someone copy that code they will have an abusement of list comprehension method and that’s not good. Better to use set comprehension.
Here is the better readable code without any deduplicate var:
duplicated_list = [1,1,2,1,3,4,1,2,3,4]
duplicated_list = list({i for i in duplicated_list})