
In this tutorial, you’ll learn how to use Pandas to drop one or more columns. When working with large DataFrames in Pandas, you’ll find yourself wanting to remove one or more of these columns. This allows you to drop data that isn’t relevant or needed for your analysis.
By the end of this tutorial, you’ll have learned:
- How to drop a Pandas column by position
- How to drop a Pandas column by name
- How to drop a Pandas column by condition
- How to drop multiple Pandas columns
- How to drop Pandas columns safely, if they exist
- And more
Table of Contents
Loading a Sample DataFrame
To follow along with the tutorial line-by-line, I have provided a sample Pandas DataFrame below. Simply copy and paste the code into your favorite code editor. If you have your own DataFrame, feel free to use that, though your results will of course vary.
You can explore the sample Pandas DataFrame below:
# Loading a Sample Pandas DataFrame
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
print(df)
# Returns:
# Name Age Location Current
# 0 Nik 33.0 Canada True
# 1 Kate 32.0 USA False
# 2 Evan 36.0 None False
# 3 Kyra NaN None TrueIn the sample DataFrame above, we have a dataset with four columns:
Name: a column containing stringsAge: a column containing a user’s ageLocation: the locations of a userCurrent: whether the user is current or not, represented as booleans
Some of these columns also contain missing data, in order to later demonstrate how to drop columns with missing data.
How to Drop a Pandas Column by Name
To drop a Pandas DataFrame column, you can use the .drop() method, which allows you to pass in the name of a column to drop. Let’s take a look at the .drop() method and the parameters that it accepts:
# Understanding the Pandas .drop() Method
import pandas as pd
df.drop(
labels=None,
axis=0,
index=None,
columns=None,
level=None,
inplace=False,
errors='raise'
)In the code block above, the various parameters and their default arguments are shown.
In order to drop a single Pandas column, you can pass in a string, representing the column, into either:
- The
labels=parameter, or - The
columns=parameter.
The parameters accept a column label or a list of column names (as you’ll see in the following section). Let’s see how we can use the labels= parameter to drop a single column:
# Dropping a Single Column Using the .drop() Method
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
df = df.drop(labels='Current', axis=1)
print(df)
# Returns:
# Name Age Location
# 0 Nik 33.0 Canada
# 1 Kate 32.0 USA
# 2 Evan 36.0 None
# 3 Kyra NaN NoneIn the above example, we passed the column we wanted to drop ('Current') into the .drop() method. However, this method is a bit verbose. We can simplify this code by using the columns= parameter instead, which replaces specifying the axis=1 parameter.
Let’s see how we can simplify dropping a single column using the .drop() method:
# Dropping a Single Column Using the .drop() Method
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
df = df.drop(columns='Current')
print(df)
# Returns:
# Name Age Location
# 0 Nik 33.0 Canada
# 1 Kate 32.0 USA
# 2 Evan 36.0 None
# 3 Kyra NaN NoneIn the code block above, we used the columns= parameter to specify the column to drop. This simplifies the code and makes it easier to read since it’s immediately clear that you want to drop columns (rather than rows).
How to Drop Pandas Columns by Name In Place
In the examples above, you learned how to drop Pandas columns by name. However, these operations happened by re-assigning the DataFrame to a variable of the same name. You can also use the operation in place, which can help with memory management. This can be especially valuable when working with a larger DataFrame.
In the code block below, you’ll learn how to drop a Pandas column by name in place:
# Dropping a Single Column Using the .drop() Method In Place
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
df.drop(columns='Current', inplace=True)
print(df)
# Returns:
# Name Age Location
# 0 Nik 33.0 Canada
# 1 Kate 32.0 USA
# 2 Evan 36.0 None
# 3 Kyra NaN NoneIn the code block above, we used the .drop() method by passing in inplace=True. This allowed for the operation to occur in place. This means that the method didn’t return a DataFrame, but modified the original.
In the following section, you’ll learn how to drop multiple columns in Pandas.
How to Drop Multiple Pandas Columns by Names
When using the Pandas DataFrame .drop() method, you can drop multiple columns by name by passing in a list of columns to drop. This method works as the examples shown above, where you can either:
- Pass in a list of columns into the
labels=argument and useindex=1 - Pass in a list of columns into the
columns=argument
Let’s see how you can use the .drop() method to drop multiple columns by name, by dropping the 'Current' and 'Location' columns:
# Drop Multiple Pandas Columns By Name
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
df = df.drop(columns=['Location', 'Current'])
# Or use:
# df = df.drop(labels=['Location', 'Current'], axis=1)
print(df)
# Returns:
# Name Age
# 0 Nik 33.0
# 1 Kate 32.0
# 2 Evan 36.0
# 3 Kyra NaNLet’s break down what we did above:
- We used the
.drop()method using thecolumns=parameter and passed in a list of columns - Alternatively, you could use the method and pass in the
labels=parameter, though you’ll need to also pass in theaxis=1argument.
Similarly, you could use the method in place, by passing in the inplace=True argument, as shown below:
# Drop Multiple Pandas Columns By Name In Place
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
df.drop(columns=['Location', 'Current'], inplace=True)
# Or use:
# df.drop(labels=['Location', 'Current'], axis=1, inplace=True)
print(df)
# Returns:
# Name Age
# 0 Nik 33.0
# 1 Kate 32.0
# 2 Evan 36.0
# 3 Kyra NaNIn the following section, you’ll learn how to use Pandas to drop a column by position or index.
How to Drop a Pandas Column by Position/Index
Dropping a Pandas column by its position (or index) can be done by using the .drop() method. The method allows you to access columns by their index position.
This is done using the df.columns attribute, which returns a list-like structure of all the columns in the DataFrame. From this, you can use list slicing to select the columns you want to drop.
To better understand how this works, let’s take a look at an example, where we’ll drop the third column:
# Dropping the Third Column by Index Position
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
df = df.drop(columns=df.columns[2])
print(df)
# Returns:
# Name Age Current
# 0 Nik 33.0 True
# 1 Kate 32.0 False
# 2 Evan 36.0 False
# 3 Kyra NaN TrueIn the .drop() method call, we pass in the selection made by indexing the df.columns list-like array to get the third item. Technically, this extracts the specific column name, which in this case would be 'Location'.
In the following section, you’ll learn how to drop multiple columns by position or index.
How to Drop Multiple Pandas Columns by Position/Index
Dropping multiple columns by position or index works in a similar way to what was shown in the previous section. By using the .drop() method, you can access columns by their position using the df.columns attribute.
To better illustrate this, let’s drop the first and third columns of our DataFrame in place:
# Dropping Multiple Columns by Index Positions
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
df.drop(columns=df.columns[[0, 2]], inplace=True)
print(df)
# Returns:
# Age Current
# 0 33.0 True
# 1 32.0 False
# 2 36.0 False
# 3 NaN TrueIt’s important to note in the example above that we used double square bracket indexing, [[0, 2]], in order to select more than one column.
In the following section, you’ll learn how to safely drop a column if it exists.
How to Drop a Pandas Column If It Exists
By default, the Pandas .drop() method will raise an error if you attempt to drop a column that doesn’t exist. This behavior is controlled by the errors= parameter, which defaults to the value of 'raise'.
The alternative argument that can be passed in is 'ignore', which will ignore any resulting errors if a column doesn’t exist.
Let’s see how we can safely remove a column if it exists in Pandas:
# Drop a Column in Pandas If It Exists
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
df = df.drop(columns='FAKE COLUMN', errors='ignore')
print(df)
# Returns:
# Name Age Location Current
# 0 Nik 33.0 Canada True
# 1 Kate 32.0 USA False
# 2 Evan 36.0 None False
# 3 Kyra NaN None TrueIn the example above, we tried to drop the column 'FAKE COLUMN'. However, since the column doesn’t exist nothing was dropped.
This removes the need to write any if-else or try-except blocks to handle these operations safely. That said, if you wanted to alert the user to a missing column, then you would need to do this.
In the code block below, we’ll use a try-except block to alert the user that a column doesn’t exist, rather than letting the error pass silently:
# Dropping a Column If It Exists Using Try-Except
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
try:
df = df.drop(columns='FAKE COLUMN')
except KeyError:
print("Column doesn't exist!")
# Returns: Column doesn't exist!In the example above, we wrapped our .drop() method call in a try-except block. The except statement checks for a KeyError and alerts the user with a print statement.
In the following section, you’ll learn how to drop a Pandas column using a condition.
How to Drop Pandas Columns by Condition
In this section, you’ll learn how to drop a Pandas column by using a condition. For example, you’ll learn how to drop columns that don’t contain the letter 'a'. This can be done, similar to the examples above, using the .drop() method. We can filter the list of column names to only include column names that include the letter we want to include.
# Dropping Columns That Meet a Condition in Pandas
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
df = df.drop(columns=[col for col in df.columns if 'a' not in col])
print(df)
# Returns:
# Name Location
# 0 Nik Canada
# 1 Kate USA
# 2 Evan None
# 3 Kyra NoneLet’s break down what we did in the code block above:
- We used the
.drop()method to drop specific columns, as indicated by using thecolumns=parameter. - We passed in a list comprehension that returned only column names from the DataFrame if the letter
'a'was not in the column name.
In the following section, you’ll learn how to drop columns containing missing values.
How to Drop Pandas Columns Containing Missing Values
There are two ways in which you may want to drop columns containing missing values in Pandas:
- Drop any column containing any number of missing values
- Drop columns containing a specific amount of missing values
In order to drop columns that contain any number of missing values, you can use the .dropna() method. Let’s take a look at how this works:
# Dropping Columns that Contain Any Number of Missing Values
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
df = df.dropna(axis=1)
print(df)
# Returns:
# Name Current
# 0 Nik True
# 1 Kate False
# 2 Evan False
# 3 Kyra TrueBy default, the .dropna() method will drop columns (when the axis is specified to be 1) where any number of values are missing. This is controlled using the default how='any' parameter.
Dropping Pandas Columns Where a Number of Records Are Missing
If we wanted to drop columns that contained a specific number of missing values, we could use the thresh= parameter, which allows you to pass in an integer representing the minimum number of records that must be non-empty in a given column.
Let’s see how we can drop columns that contain at least two missing values:
# Dropping Columns That Contain A Minimum Number of Missing Values
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
df = df.dropna(axis=1, thresh=3)
print(df)
# Returns:
# Name Age Current
# 0 Nik 33.0 True
# 1 Kate 32.0 False
# 2 Evan 36.0 False
# 3 Kyra NaN TrueLet’s break down what the code above is doing, as it’s not immediately clear:
- The
thresh=parameter determines the number of of non-missing values that must exist at a minimum. - In this case, we specified that there must be at least three non-missing values. This implies, then, that we would have 2 or more missing values, given the length of the DataFrame.
Dropping Pandas Columns Where a Percentage of Records Are Missing
Arguably, a better way to set this threshold is by using the percentage of values that are missing. Say you wanted to drop columns where 50% or more values were missing. You could do this using the .isnull() method, combined with the .drop() method.
Using the .isnull() method, we can calculate the percentage of records that are missing in a column and filter this down to only columns with more values missing than a given threshold.
Let’s see how we can drop columns where 50% or more values are missing:
# Dropping Columns Where 50%+ Values are Missing
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
columns = df.columns[df.isnull().mean() >= 0.5]
df = df.drop(columns=columns)
print(df)
# Returns:
# Name Age Current
# 0 Nik 33.0 True
# 1 Kate 32.0 False
# 2 Evan 36.0 False
# 3 Kyra NaN TrueLet’s break down what we did in the code block above:
- We defined a new variable,
columns, which chains the.isnull()and.mean()methods together to return a percentage of the number of missing values in each column. - This returns an array of boolean values, representing if the given column meets the condition or not.
- We then sliced the list of columns using this boolean array to filter down to columns to drop.
- In this case, we only dropped the
'Location'column, since 50% of the values were missing.
In the following section, you’ll learn how to drop Pandas columns following a specific column.
How to Drop Pandas Columns After a Specific Column
We can also use the .loc selector to drop columns based on their name. This allows us to define columns we want to drop, following a specific column. The .loc accessor selects rows and columns and allows us to define slices of records to include.
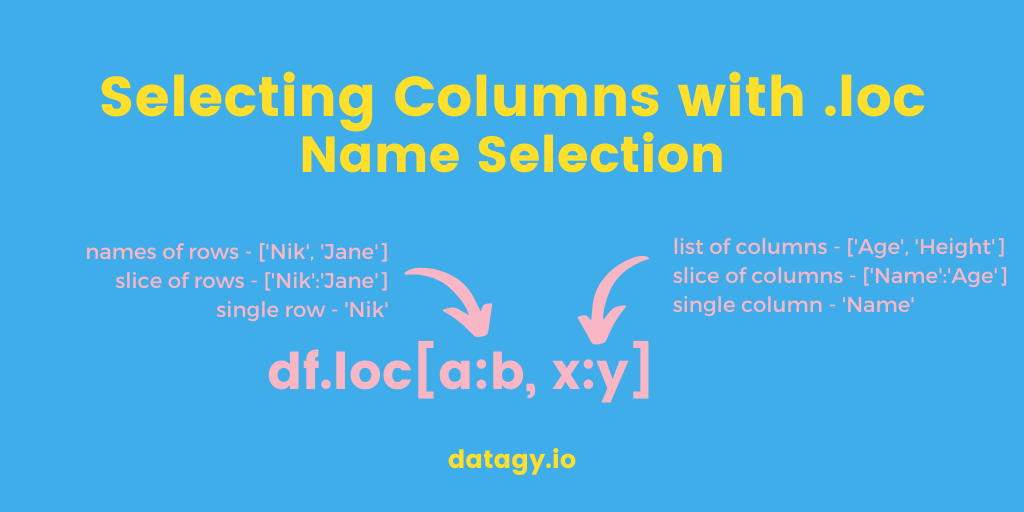
Say we wanted to drop all columns following the 'Age' column, we could write the following:
# Dropping Columns After a Specific Column Name
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
df = df.loc[:, :'Age']
print(df)
# Returns:
# Name Age
# 0 Nik 33.0
# 1 Kate 32.0
# 2 Evan 36.0
# 3 Kyra NaNThe .loc accessor specifies that we want to keep all rows (indicated by the first :) and keep all columns up to the 'Age' column. As we can see, the columns that follow that column are dropped!

Similarly, we can use the .iloc accessor to drop any columns before or after a given column number.
Say we wanted to drop any column before the third column. We could write the following:
# Dropping Columns Before a Specific Column Number
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
df = df.iloc[:, 2:]
print(df)
# Returns:
# Location Current
# 0 Canada True
# 1 USA False
# 2 None False
# 3 None TrueThe .iloc accessor allows us to provide slices of rows and columns we want to select. Any columns, in this case, that aren’t selected are dropped.
How to Drop Pandas Columns of Specific Data Types
In order to drop Pandas columns of a specific data type, you can use the .select_dtypes() method. This method allows you to pass in a list of data types that you want to drop from the DataFrame.
Let’s take a look at an example of how we can use the method to drop columns that are boolean data types:
# Dropping Pandas Columns of a Specific Data Type
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
df = df.select_dtypes(exclude=['boolean'])
print(df)
# Returns:
# Name Age Location
# 0 Nik 33.0 Canada
# 1 Kate 32.0 USA
# 2 Evan 36.0 None
# 3 Kyra NaN NoneIn the above example, we used the .select_dtypes() method with the exclude= parameter. This parameter accepts a list of different data types to exclude. Any column that matches the excluded data type will be dropped from the resulting DataFrame.
How to Pop Pandas Columns
In this section, you’ll learn how to use the Pandas .pop() method to drop a column and save it to a resulting variable. This can be particularly helpful in machine learning problems, where you may want to remove a column representing the target variable. In these cases, you’ll often want to save that column as a Series of its own.
Let’s see how we can use the .pop() method to drop the 'Name' column from the DataFrame and save it to its own Series:
# Popping a Pandas DataFrame Column
import pandas as pd
df = pd.DataFrame({
'Name': ['Nik', 'Kate', 'Evan', 'Kyra'],
'Age': [33, 32, 36, None],
'Location': ['Canada', 'USA', None, None],
'Current': [True, False, False, True]})
names = df.pop('Name')
print(df)
# Returns:
# Age Location Current
# 0 33.0 Canada True
# 1 32.0 USA False
# 2 36.0 None False
# 3 NaN None TrueIn the code block above, we popped the column 'Name' and assigned it to the variable names. This means that the column was dropped from the DataFrame a Pandas Series was created containing the values from that column.
Conclusion
In this tutorial, you learned a number of useful ways in which you can use Pandas to drop columns from a DataFrame. Being able to work with DataFrames is an important skill for data analysts and data scientists alike. Understanding the vast flexibility that Pandas offers in working with columns can make your workflow significantly easier and more streamlined!
Throughout this tutorial, you learned how to use the Pandas .drop() method, the .dropna() method, the .pop() method and the .loc and .iloc accessors. All of these methods allow you to drop columns in a Pandas DataFrame in different ways.
Additional Resources
To learn more about related topics, check out the tutorials below: