
Evaluating the performance of classification models is crucial in machine learning, as it helps us understand how well our models are making predictions. One of the most effective ways to do this is by using a confusion matrix, a simple yet powerful tool that provides insights into the types of errors a model makes. In this tutorial, we will dive into the world of confusion matrices, exploring their components, the differences between binary and multi-class matrices, and how to interpret them.
By the end of this tutorial, you’ll have learned the following:
- What confusion matrices are and how to interpret them
- How to create them using Sklearn’s powerful functions
- How to create common confusion matrix metrics, such as accuracy and recall, using sklearn
- How to visualize a confusion matrix using Sklearn and Seaborn
Table of Contents
What You’ll Learn About a Confusion Matrix in Python

What is a Confusion Matrix?
Understand what it is first

Creating a Confusion Matrix
Learn how to create a confusion matrix in Sklearn

Visualizing a Confusion Matrix
Visualize your confusion matrix using Seaborn
The Quick Answer: Use Sklearn’s confusion_matrix
To easily create a confusion matrix in Python, you can use Sklearn’s confusion_matrix function, which accepts the true and predicted values in a classification problem.
# Creating a Confusion Matrix in Python with sklearn
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
# Create a Model
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
data.data, data.target, test_size=0.2)
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# Create a Confusion Matrix
print(confusion_matrix(y_test, y_pred))
# Returns:
# [[37 3]
# [ 1 73]]Understanding a Confusion Matrix
A confusion matrix, also known as an error matrix, is a powerful tool used to evaluate the performance of classification models. The matrix is a tabular format that shows predicted values against their actual values.
This allows us to understand whether the model is performing well or not. Similarly, it allows you to identify where the model is making mistakes.
Definition and Explanation of a Confusion Matrix
A confusion matrix is a table that displays the number of correct and incorrect predictions made by a classification model. The table is presented in such a way that:
- The rows represent the instances of the actual class, and
- The columns represent the instances of the predicted class.
Take a look at the visualization below to see what a simple confusion matrix looks like:

Let’s break down what these sections of a confusion matrix mean.
Components of a Confusion Matrix
Similar to the image above, a confusion matrix is made up of four main components:
- True Positives (TP): instances where the model correctly predicted the positive class.
- True Negatives (TN): instances where the model correctly predicted the negative class.
- False Positives (FP): instances where the model incorrectly predicted the positive class (also known as Type I error).
- False Negatives (FN): instances where the model incorrectly predicted the negative class (also known as Type II error).

Understanding a Multi-Class Confusion Matrix
So far, we have discussed confusion matrices in the context of binary classification problems. This means that the model predicts something to either be one thing or not.
However, confusion matrices can also be used for multi-class classification problems, where there are more than two classes to predict. In this section, you’ll learn about the concept of multi-class confusion matrices and understand their components and differences from binary confusion matrices.
A multi-class confusion matrix builds on a simple, binary confusion matrix, designed to evaluate the performance of classification models with more than two classes. A multi-class confusion matrix is an n x n table, where n represents the number of classes in the problem.
Each row of the matrix corresponds to the instances of the actual class, and each column corresponds to the instances of the predicted class.
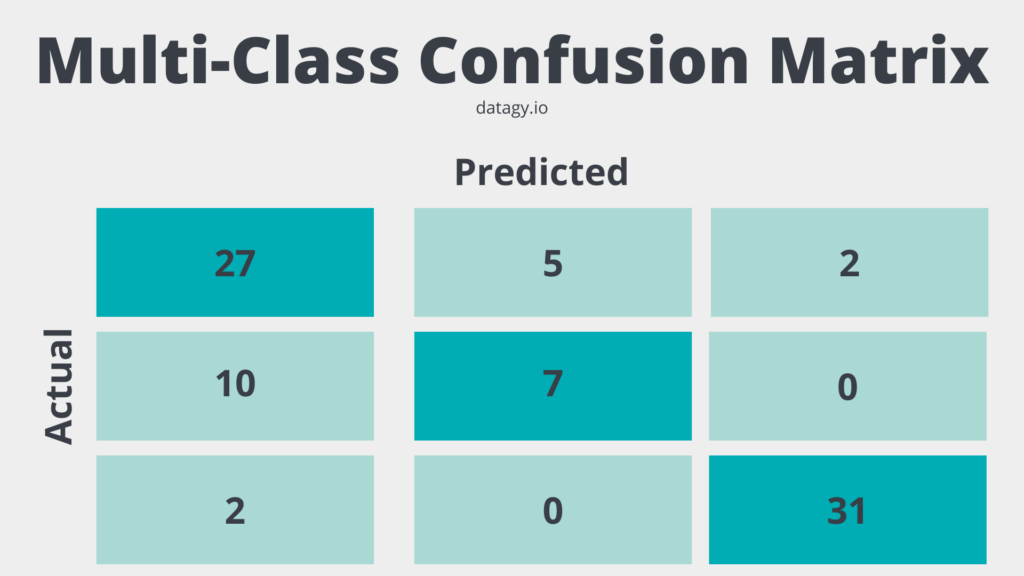
Components of a Multi-Class Confusion Matrix
A multi-class confusion matrix is different from a binary confusion matrix. Let’s explore how this is different:
- Diagonal elements: values along the diagonal represent the number of instances where the model correctly predicted the class. They are equivalent to True Positives (TP) in the binary case, but for each class.
- Off-diagonal elements: all values that aren’t on the diagonal represent the number of instances where the model incorrectly predicted the class. They correspond to False Positives (FP) and False Negatives (FN) in the binary case, but for each combination of classes.
In a multi-class confusion matrix, the sum of all diagonal elements gives the total number of correct predictions, and the sum of all off-diagonal elements gives the total number of incorrect predictions.
Differences and Similarities Between Binary and Multi-Class Confusion Matrices
While binary and multi-class confusion matrices serve the same purpose of evaluating classification models, there are some key differences and similarities between them:
- Structure: a binary confusion matrix is a 2 x 2 table, whereas a multi-class confusion matrix is a n x n table, where n is the number of classes.
- Components of a confusion matrix: Both binary and multi-class confusion matrices have diagonal elements representing correct predictions. Similarly, the off-diagonal elements represent incorrect predictions. However, in the multi-class case, there are multiple True Positives, False Positives, and False Negatives for each combination of classes.
Knowing how to work with both binary and multi-class confusion matrices will be essential in evaluating different types of machine learning models.
Importance of Using a Confusion Matrix for Classification Problems
A confusion matrix is useful for evaluating classification models by allowing you to understand the types of errors that a model is making. In particular, a classification matrix allows you to identify if a model is biased toward a particular class. Similarly, it allows you to better understand if a model is either too sensitive or too conservative.
How to Interpret a Confusion Matrix
Understanding the components of a confusion matrix is just the first step. In this section, you will learn how to interpret a confusion matrix. You’ll also learn how to calculate different performance metrics that can help us make informed decisions about your classification model.
Understanding the Components of a Confusion Matrix
As you learned earlier, a confusion matrix consists of four components: True Positives, True Negatives, False Positives, and False Negatives. To interpret a confusion matrix, we can examine these components and understand how they relate to the model’s performance.
Calculating Performance Metrics Using a Confusion Matrix
The values of a confusion matrix allow you to calculate a number of different performance metrics, including accuracy, precision, recall, and the F1 score. Let’s break these down a little bit more:
- Accuracy: The ratio of correct predictions (TP + TN) to the total number of predictions (TP + TN + FP + FN).
- Precision: The ratio of true positive predictions (TP) to the total number of positive predictions (TP + FP).
- Recall (Sensitivity): The ratio of true positive predictions (TP) to the total number of actual positive instances (TP + FN).
- F1 Score: The harmonic mean of precision and recall, which provides a balanced measure of the model’s performance.
Analyzing the Results and Making Informed Decisions
By calculating the performance metrics above, you’ll be able to better analyze how well your model is performing. By understanding the confusion matrix and the performance metrics, we can make informed decisions about our model, such as adjusting the classification threshold, balancing the dataset, or selecting a different algorithm to improve its performance.
For example, a model that shows high accuracy might indicate that the model is performing well. On the other hand, a model that has low precision or recall can indicate that a model may have issues in identifying classes correctly.
Creating a Confusion Matrix in Python
Now that you have learned how confusion matrices are valuable tools for evaluating classification problems in machine learning, let’s dive into how to create them using Python with sklearn. Sklearn is an invaluable tool for creating machine-learning models in Python.
Dataset Preparation and Model Training
For the purposes of this tutorial, we’ll be creating a confusion matrix using the sklearn breast cancer dataset, which identifies whether a tumor is malignant or benign. We won’t go through the model selection, creation, or prediction process in this tutorial. However, we’ll set up the baseline model so that we can create the confusion matrix.
# Loading a Binary Classification Model in Sklearn
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42)
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)In the code block above, we imported a number of different functions and classes from Sklearn. In particular, we followed best practices by splitting our dataset into training and testing datasets using the train_test_split function.
Generating a Confusion Matrix Using Sklearn
Now that we have a model created, we can build our first confusion matrix. Let’s take a look at the function and see what parameters it offers. The sklearn.metrics.confusion_matrix is a function that computes a confusion matrix and has the following parameters:
y_true: true labels for the test data.y_pred: predicted labels for the test data.labels: optional, list of labels to index the matrix. This may be used to reorder or select a subset of labels. If None is given, all labels are used.sample_weight: optional, sample weights.normalize: If set to ‘true’, the rows of the confusion matrix are normalized so that they sum up to 1. If set to ‘pred’, the columns of the confusion matrix are normalized so that they sum up to 1. If set to ‘all’, all values in the confusion matrix are normalized so that they sum up to 1. If set to None, no normalization is performed (default).
The only required parameters are the y_true and y_pred parameters. We created these in our previous code block. Let’s see how we can create our first confusion matrix:
# Create a confusion matrix
print(confusion_matrix(y_test, y_pred))
# Returns:
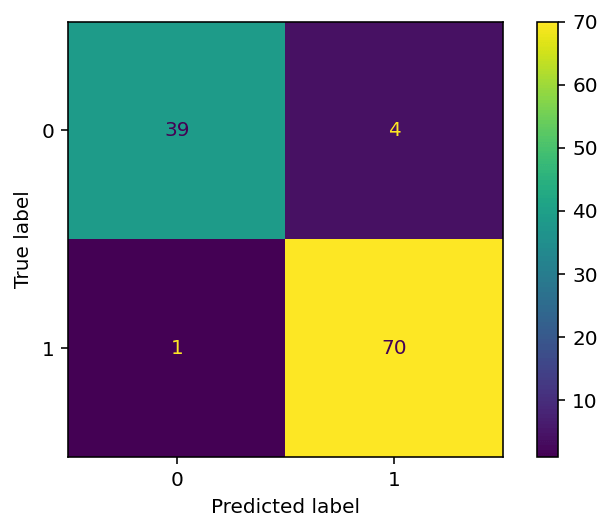
# [[37 3]
# [ 1 73]]In this example, there were:
- 37 true positives (i.e., cases where the model correctly predicted that the patient had breast cancer),
- 3 false positives (i.e., cases where the model incorrectly predicted that the patient had breast cancer),
- 1 false negative (i.e., a case where the model incorrectly predicted that the patient did not have breast cancer), and
- 73 true negatives (i.e., cases where the model correctly predicted that the patient did not have breast cancer).
Let’s now take a look at how we can interpret the generated confusion matrix.
Interpreting the Generated Confusion Matrix
The way in which you interpret a confusion matrix is determined by how accurate your model needs to be. For example, in our example, we are predicting whether or not someone has cancer. In these cases, the accuracy of our model is incredibly important. Even infrequent misclassifications can have significant impacts.
On the other hand, working with datasets with less profound consequences, there may be a larger margin for error. In my experience, it’s important to focus on truly understand the sensitivity and importance of misclassifications.
We can use Sklearn to calculate the accuracy, precision, recall, and F1 scores to help interpret our confusion matrix. Let’s see how we can do this in Python using sklearn:
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# Calculate the accuracy
accuracy = accuracy_score(y_test, y_pred)
# Calculate the precision
precision = precision_score(y_test, y_pred)
# Calculate the recall
recall = recall_score(y_test, y_pred)
# Calculate the f1 score
f1 = f1_score(y_test, y_pred)
# Print the results
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)
print("F1 Score:", f1)
# Returns:
# Accuracy: 0.956140350877193
# Precision: 0.9459459459459459
# Recall: 0.9859154929577465
# F1 Score: 0.9655172413793103Recall that these scores represent the following:
- Accuracy: The ratio of correct predictions (TP + TN) to the total number of predictions (TP + TN + FP + FN).
- Precision: The ratio of true positive predictions (TP) to the total number of positive predictions (TP + FP).
- Recall (Sensitivity): The ratio of true positive predictions (TP) to the total number of actual positive instances (TP + FN).
- F1 Score: The harmonic mean of precision and recall, which provides a balanced measure of the model’s performance.
We can simplify printing these values even further by using the sklearn classification_report function, which takes the true and predicted values as input:
# Using classification_report to Print Scores
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred))
# Returns:
# precision recall f1-score support
# 0 0.97 0.91 0.94 43
# 1 0.95 0.99 0.97 71
# accuracy 0.96 114
# macro avg 0.96 0.95 0.95 114
# weighted avg 0.96 0.96 0.96 114Finally, let’s take a look at how we can visualize the confusion matrix in Python, using Seaborn.
Visualizing a Confusion Matrix in Python
Sklearn provides a helpful class to help visualize a confusion matrix. While other tutorials will point you to the plot_confusion_matrix function, this function was recently deprecated. Because of this, it’s important to use the ConfusionMatrixDisplay class.
The ConfusionMatrixDisplay class lets you pass in a confusion matrix and the labels of your classes. You can then visualize the matrix by applying the .plot() method to your object. Take a look at what this looks like below:
# Plotting a Confusion Matrix with Sklearn
from sklearn.metrics import ConfusionMatrixDisplay
import matplotlib.pyplot as plt
conf_matrix = confusion_matrix(y_true=y_test, y_pred=y_pred)
vis = ConfusionMatrixDisplay(confusion_matrix=conf_matrix, display_labels=model.classes_)
vis.plot()
plt.show()In the code block above, we passed our confusion matrix into the ConfusionMatrixDisplay class constructor. We also included our display labels by accessing the classes. Finally, we applied the .plot() method and used the Matplotlib show() function to visualize the image below:
In the following section, you’ll learn how to plot a confusion matrix using Seaborn.
Using Seaborn to Plot a Confusion Matrix
Seaborn is a helpful Python data visualization library built on top of Matplotlib. Its mission is to make hard things easy, allowing you to create complex visualizations using a simple API.
Plotting a confusion matrix is similar to plotting a heatmap in Seaborn, indicating where values are higher or lower visually. In order to do this, let’s plot a confusion matrix for another model, where we have more than a binary class.
If you’re unfamiliar with KNN in Python using Sklearn, you can follow along with the tutorial link here. That said, the end result of the code block is a model with three classes, rather than two:
# Creating a Model with 3 Classes
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
import seaborn as sns
df = sns.load_dataset('penguins')
df = df.dropna()
X = df.drop(columns = ['species', 'sex', 'island'])
y = df['species']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 100)
clf = KNeighborsClassifier(p=1)
clf.fit(X_train, y_train)
predictions = clf.predict(X_test)In the code block above, we created a model that predicts three different classes. In order to plot the confusion matrix for this model, we can use the code below:
# Plotting a Confusion Matrix in Seaborn
conf_matrix = confusion_matrix(y_test, predictions, labels=clf.classes_)
sns.heatmap(conf_matrix,
annot=True,
fmt='g',
xticklabels=clf.classes_,
yticklabels=clf.classes_,
)
plt.ylabel('Prediction',fontsize=13)
plt.xlabel('Actual',fontsize=13)
plt.title('Confusion Matrix',fontsize=17)
plt.show()In the code block above, we used the heatmap function in Seaborn to plot our confusion matrix. We also modified the labels and titles using special functions.
This returned the following image:
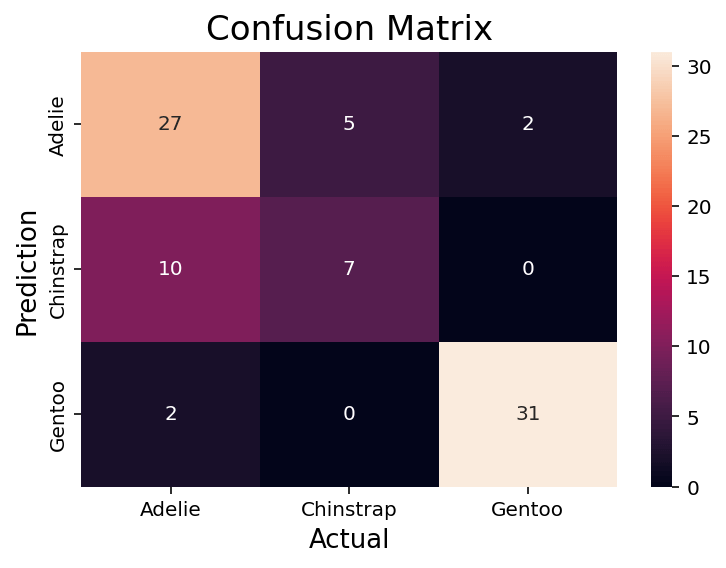
We can see that this returns an image very similar to the Sklearn one. One benefit of this approach is how declarative and familiar it is. If you’re familiar with Seaborn or matplotlib, customizing the confusion matrix is quite simple.
Frequently Asked Questions
A confusion matrix in Python is a table that displays the number of correct and incorrect predictions made by a classification model. It helps in evaluating the performance of the model by comparing its predictions against the actual values. Python libraries like sklearn provide functions to create and visualize confusion matrices, making it easier to analyze and interpret the results.
A confusion matrix tells you how well a classification model is performing by showing the number of correct and incorrect predictions. It highlights the instances where the model correctly predicted the positive and negative classes (True Positives and True Negatives) and the instances where the model incorrectly predicted the positive and negative classes (False Positives and False Negatives). By analyzing the confusion matrix, you can identify the types of errors the model is making, and make informed decisions to improve its performance.
The sklearn library provides a function called confusion_matrix that can be used to create a confusion matrix for a classification model. To use it, you need to pass the true labels (y_true) and the predicted labels (y_pred) as arguments. The function returns a confusion matrix that can be printed or visualized using other libraries like matplotlib or Seaborn.
Yes, you can use a confusion matrix for multi-class classification problems. In the case of multi-class classification, the confusion matrix is an n x n table, where n represents the number of classes. Each row corresponds to the instances of the actual class, and each column corresponds to the instances of the predicted class. The diagonal elements represent correct predictions, while the off-diagonal elements represent incorrect predictions. The process of interpreting a multi-class confusion matrix is similar to that of a binary confusion matrix, with the main difference being the presence of multiple classes.
Conclusion
In this tutorial, we have explored the concept of confusion matrices and their importance in evaluating the performance of classification models. We’ve learned about the components of binary and multi-class confusion matrices, how to interpret them, and how to calculate various performance metrics such as accuracy, precision, recall, and F1 score. Additionally, we’ve demonstrated how to create and visualize confusion matrices in Python using sklearn and Seaborn.
As you continue to work on machine learning projects, understanding and utilizing confusion matrices will be an invaluable skill in assessing the performance of your classification models. By identifying the types of errors a model makes, you can make informed decisions to improve its performance, such as adjusting the classification threshold, balancing the dataset, or selecting a different algorithm. Keep practicing and experimenting with confusion matrices, and you’ll be well-equipped to tackle the challenges of evaluating classification models in your future projects.
To learn more about the Sklearn confusion_matrix function, check out the official documentation.